||
上一篇 MySQL8.0 优化器介绍(一)介绍了成本优化模型的三要素:表关联顺序,与每张表返回的行数(过滤效率),查询成本。而join算法又是影响表关联效率的首要因素。
join在MySQL 是一个如此重要的章节,毫不夸张的说,everything is a join。
截止到本文写作时,MySQL8.0.32 GA已经发行,这里主要介绍三大join:NL(Nested Loop),BNL(Block Nested Loop),HASH JOIN
MySQL5.7之前,都只有NL,它实现简单,适合索引查找。
几乎每个人都可以手动实现一个NL。
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country
INNER JOIN world.city
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
##执行计划类似如下:
-> Nested loop inner join
-> Filter: (country.Continent = 'Asia')
-> Table scan on country
-> Index lookup on city using CountryCode
(CountryCode=country.`Code`)
##python 代码实现一个NL
result = []
for country_row in country:
if country_row.Continent == 'Asia':
for city_row in city.CountryCode['country_row.Code']:
result.append(join_rows(country_row, city_row))图示化一个NL
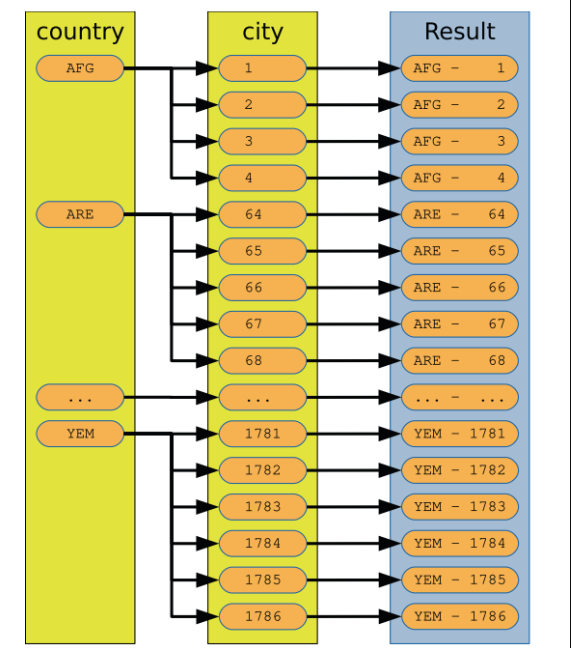
NL的限制:通常多个表join,小表在前做驱动表,被驱动表有索引检索,效率会高一些。(官方手册上没有full outer join ,full join 语法,实际支持full join)
举个例子 多表join 且关联表不走索引:
#人为干预计划,走性能最差的执行路径。
SELECT /*+ NO_BNL(city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
**************************** 1. row ****************************
rows_examined: 208268
rows_sent: 1766
latency: 44.83 ms
##对比一下优化器 自动优化后的
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country
INNER JOIN world.city
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
*************************** 1. row ***************************
rows_examined: 2005
rows_sent: 1766
latency: 4.36 ms
1 row in set (0.0539 sec)块嵌套循环算法是嵌套循环算法的扩展。它也被称为BNL算法。连接缓冲区用于收集尽可能多的行,并在第二个表的一次扫描中比较所有行,而不是逐个提交第一个表中的行。这可以大大提高NL在某些查询上的性能。
hash join是在MySQL8.0.18引进的,下面的sql,使用了NO_HASH_JOIN(country,city) 的提示,并且两表的join 字段上的索引被忽略,目的是为了介绍BNL特性。
SELECT /*+ NO_HASH_JOIN(country,city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
##使用python伪代码来解释一下 BNL
result = []
join_buffer = []
for country_row in country:
if country_row.Continent == 'Asia':
join_buffer.append(country_row.Code)
if is_full(join_buffer):
for city_row in city:
CountryCode = city_row.CountryCode
if CountryCode in join_buffer:
country_row = get_row(CountryCode)
result.append(
join_rows(country_row, city_row))
join_buffer = []
if len(join_buffer) > 0:
for city_row in city:
CountryCode = city_row.CountryCode
if CountryCode in join_buffer:
country_row = get_row(CountryCode)
result.append(join_rows(country_row, city_row))
join_buffer = []图示化一个BNL
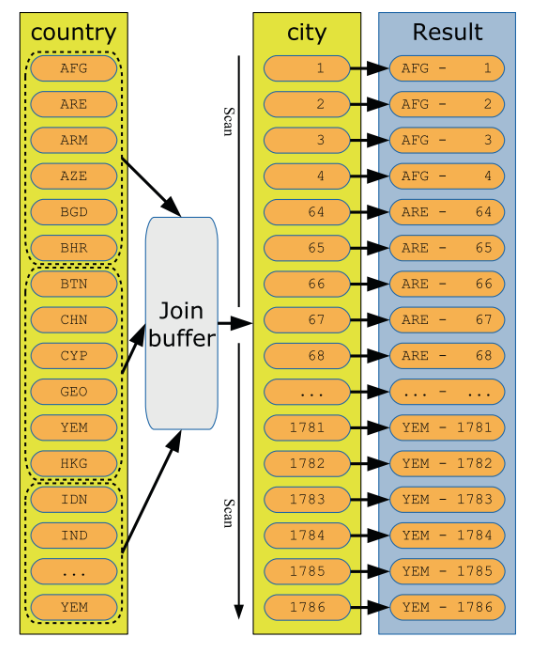
注意图里的join_buffer,在MySQL5.7上使用sysbench压测读写场景,压力上不去,主要就是因为BNL 算法下,join_buffer_size的设置为默认值。适当调整几个buffer后,tps得到显著提高。join buffer对查询影响,也可以用下面的例子做一个量化说明。
SELECT /*+ NO_HASH_JOIN(country,city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
*************************** 1. row ***************************
rows_examined: 4318
rows_sent: 1766
latency: 16.87 ms
1 row in set (0.0490 sec)
#人为干预计划,走性能最差的执行路径。
SELECT /*+ NO_BNL(city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
**************************** 1. row ****************************
rows_examined: 208268
rows_sent: 1766
latency: 44.83 ms
在两表join,且join字段不使用索引的前提下,BNL +join_buffer 性能远大于 NL 使用BNL 有几个点需要注意。(我实在懒得全文翻译官方文档了)
可以通过 optimizer switch 配置BNL() 、 NO_BNL()
BNL 特别擅长在non-indexed joins 的场景,很多时候性能优于hash join。As of version 8.0.20, block nested-loop joins are no longer used; instead, a hash join has replaced it.

Hash Join 作为大杀器在 MySQL8.0.18引入,期间有过引起内存和文件句柄大量消耗的线上问题,但是不妨碍它作为一个join算法的重大突破,特别适合大表与大表的无索引join。某些场景甚至比NL+index join 更快。(当然比起oracle 上的hash join 依然弱爆了,40w * 40w 的大表查询,MySQL优化到极致在10s左右,oracle在1s 水平,相差一个数量级。
思考:MySQL、Oracle都是hash join,为何差距如此大?MySQL hash join 可以哪些方面进行性能提高?
业界主要有两大方向
参考文档(https://zhuanlan.zhihu.com/p/589601705)
大家不妨看看 MySQL工程师的worklog, 内容很精彩(https://dev.mysql.com/worklog/task/?id=2241)
可以看出国外大厂强大的标准化的it生产能力,一个功能从需求到实现经历了哪些关键步骤。
MySQL 的Hash join是一个内存hash+磁盘hash的混合扩展。为了不让hash join 溢出join buffer,需要加大内存设置,使用磁盘hash时,需要配置更多的文件句柄数。尽管有disk hash ,但实际干活的还是in-memory hash。
内存hash 有两个阶段:
当hashes of build table 不足以全部放进内存时,MySQL会自动切换到on-disk的扩展实现(基于 GRACE hash join algorithm)。在build phase阶段,join buffer满,就会发生 in-mem hash 向on-disk hash 转换。
on-disk algorithm 包含3个步骤:
无论是内存hash还是磁盘hash,都使用xxHash64 hash function。xxHash64有足够快,hash质量好(reducing the number of hash collisions)的特点
BNL不会被选中的时候,MySQL就会选用hash join。
在整理这篇资料时,对要使用的哈希连接算法存在以下要求:
用一个例子来说明一下hash join:
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
#用一段伪代码翻译一下
result = []
join_buffer = []
partitions = 0
on_disk = False
for country_row in country:
if country_row.Continent == 'Asia':
hash = xxHash64(country_row.Code)
if not on_disk:
join_buffer.append(hash)
if is_full(join_buffer):
# Create partitions on disk
on_disk = True
partitions = write_buffer_to_disk(join_buffer)
join_buffer = []
else
write_hash_to_disk(hash)
if not on_disk:
for city_row in city:
hash = xxHash64(city_row.CountryCode)
if hash in join_buffer:
country_row = get_row(hash)
city_row = get_row(hash)
result.append(join_rows(country_row, city_row))
else:
for city_row in city:
hash = xxHash64(city_row.CountryCode)
write_hash_to_disk(hash)
for partition in range(partitions):
join_buffer = load_build_from_disk(partition)
for hash in load_hash_from_disk(partition):
if hash in join_buffer:
country_row = get_row(hash)
city_row = get_row(hash)
result.append(join_rows(country_row, city_row))
join_buffer = []
与所使用的实际算法相比,所描述的算法稍微简化了一些。
真正的算法必须考虑哈希冲突,
而对于磁盘上的算法,某些分区可能会变得太大而无法放入连接缓冲区,
在这种情况下,它们会被分块处理,以避免使用比配置的内存更多的内存图示化一下 in-mem hash 算法:
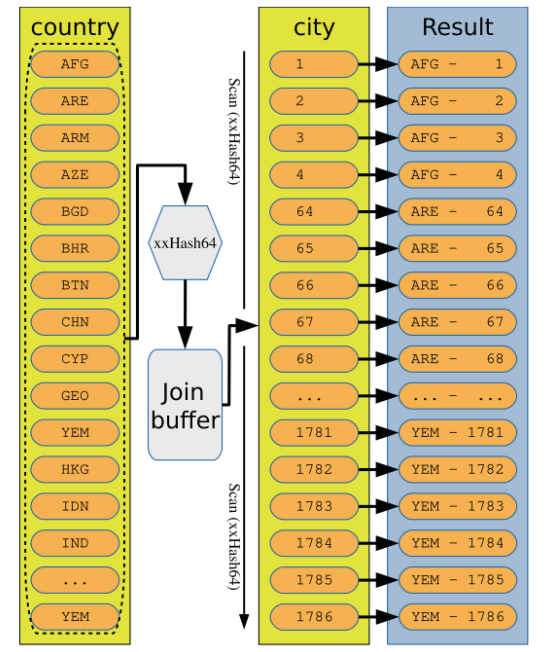
量化一下hash join 的成本
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
**************************** 1. row ****************************
rows_examined: 4318
rows_sent: 1766
latency: 3.53 ms从本文的例子中,rows_examined 的角度来看 index_join 下的NL(2005) 优于 无索引join条件下的BNL (4318)= 无索引join条件下的 hash join。但是当数据量发生变化,可能结果就不一样了,现实中也没有绝对的性能好坏规则(如果有,基于规则的成本计算就能很好处理的查询问题,实际上更值得信赖的是成本估算),hash join与NL,BNL 的优越比较,列出几点,当作纸上谈兵 :
Hash Join 最大的好处在于提升多表无索引关联时的查询性能。具体NL,BNL,HASH JOIN谁更适合用于查询计划,实践才是最好的证明。
同样可以使用HASH_JOIN() 和 NO_HASH_JOIN() 的hint 来影响查询计划。
MySQL8.0 关于支持的三种high-level 连接策略的讨论暂时到此结束。下来可以自己去查一下 anti, semi, and outer joins。
更多细节 参考
(https://dev.mysql.com/doc/refman/8.0/en/select-optimization.html)(https://dev.mysql.com/doc/refman/8.0/en/semijoins.html)
还有一些 关于join的lower-level优化值得考虑,下篇文章分解。
合作电话:010-64087828
社区邮箱:greatsql@greatdb.com


