||
本章使用的测试数据库为GreatSQL8.0.25版本
(Wed Aug 3 16:17:03 2022)[root@GreatSQL][(none)]>select version();+-----------+| version() |+-----------+| 8.0.25-16 |+-----------+1 row in set (0.00 sec)在实际工作中,我们常常将Redis作为缓存与MySQL配合来使用,当有请求的时候,首先会从缓存中进行查找,如果存在就直接取出。如果不存在再访问数据库,这样就提升了读取的效率,也减少了对后端数据库的访问压力。Redis的缓存架构是高并发架构中非常重要的一环。
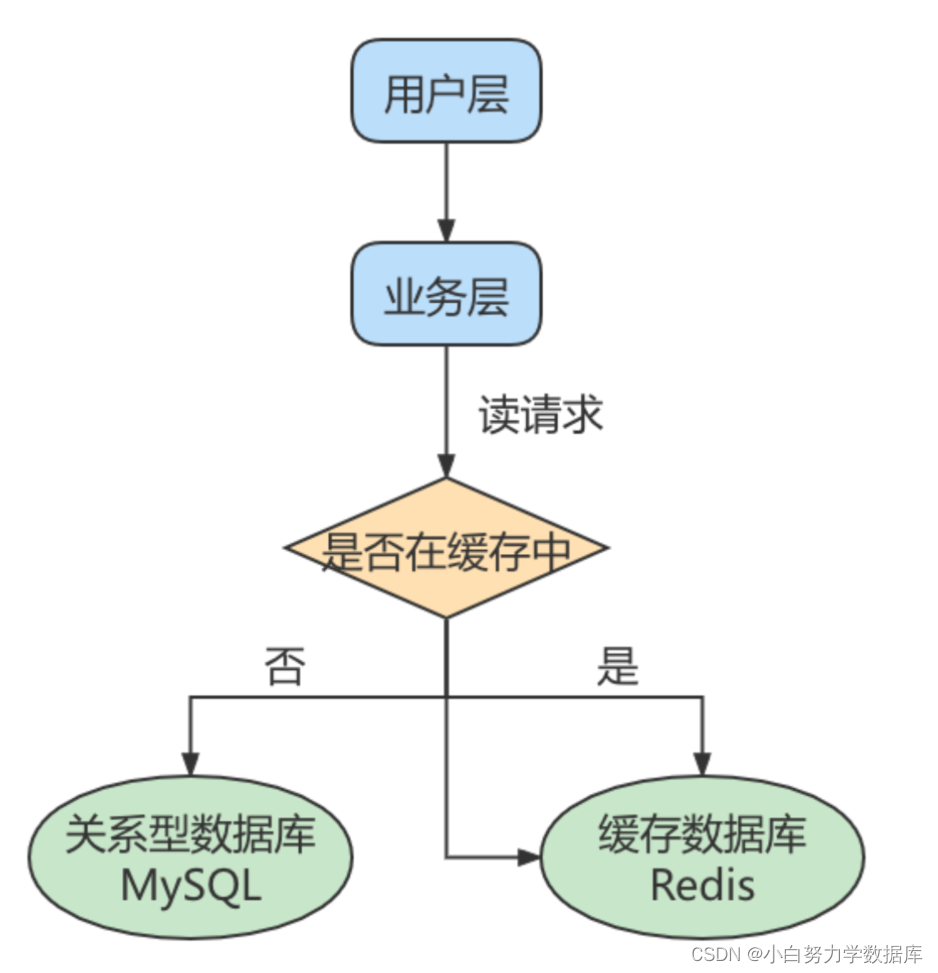
此外,一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是采用数据库集群的方案,做主从架构、进行读写分离,这样同样可以提升数据库的并发处理能力。但并不是所有的应用都需要对数据库进行主从架构的设置,毕竟设置架构本身是有成本的。
如果我们的目的在于提升数据库高并发访问的效率,那么首先考虑的是如何优化SQL和索引,这种方式简单有效;其次才是采用缓存的策略,比如使用 Redis将热点数据保存在内存数据库中,提升读取的效率;最后才是对数据库采用主从架构,进行读写分离。
主从同步设计不仅可以提高数据库的吞吐量,还有以下 3 个方面的作用。
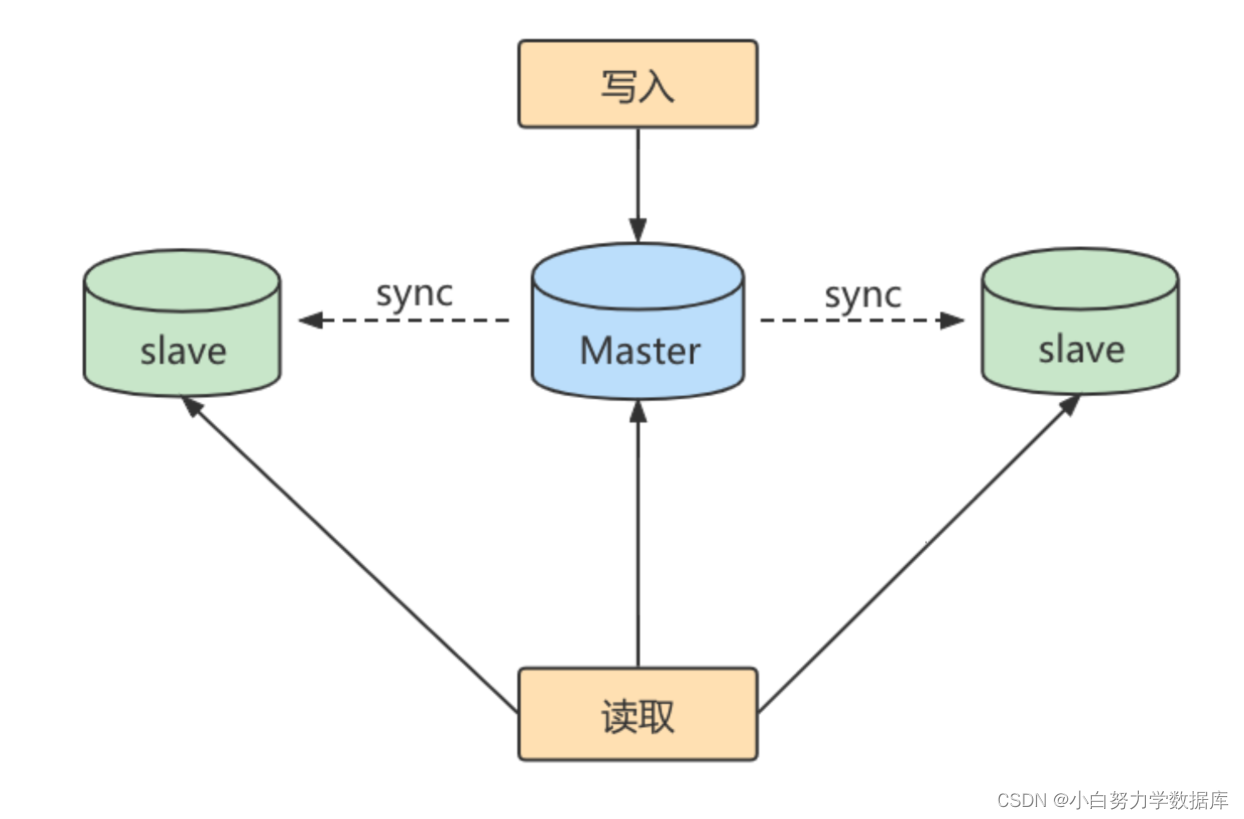
第 1 个作用:读写分离。 我们可以通过主从复制的方式来同步数据,然后通过读写分离提高数据库并发处理能力
在这里插入图片描述
其中一个是Master主库,负责写入数据,我们称之为:写库。
其它都是Slave从库,负责读取数据,我们称之为:读库。
当主库进行更新的时候,会自动将数据复制到从库中,而我们在客户端读取数据的时候,会从从库中进行读取。
面对“读多写少”的需求,采用读写分离的方式,可以实现更高的并发访问。同时,我们还能对从服务器进行负载均衡,让不同的读请求按照策略均匀地分发到不同的从服务器上,让读取更加顺畅。读取顺畅的另一个原因,就是减少了锁表的影响,比如我们让主库负责写,当主库出现写锁的时候,不会影响到从库进行SELECT的读取。
第 2 个作用就是数据备份。 我们通过主从复制将主库上的数据复制到了从库上,相当于是一种热备份机制,也就是在主库正常运行的情况下进行的备份,不会影响到服务。
第 3 个作用是具有高可用性。 数据备份实际上是一种冗余的机制,通过这种冗余的方式可以换取数据库的高可用性,也就是当服务器出现故障或宕机的情况下,可以切换到从服务器上,保证服务的正常运行。
关于高可用性的程度,我们可以用一个指标衡量,即正常可用时间/全年时间。比如要达到全年99.999%的时间都可用,就意味着系统在一年中的不可用时间不得超过365*24*60*(1-99.999%)=5.256分钟(含系统崩溃的时间、日常维护操作导致的停机时间等),其他时间都需要保持可用的状态。
实际上,更高的高可用性,意味着需要付出更高的成本代价。在现实中我们需要结合业务需求和成本来进行选择。
Slave会从Master读取binlog来进行数据同步。
三个线程
实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于3个线程来操作,一个主库线程,两个从库线程。
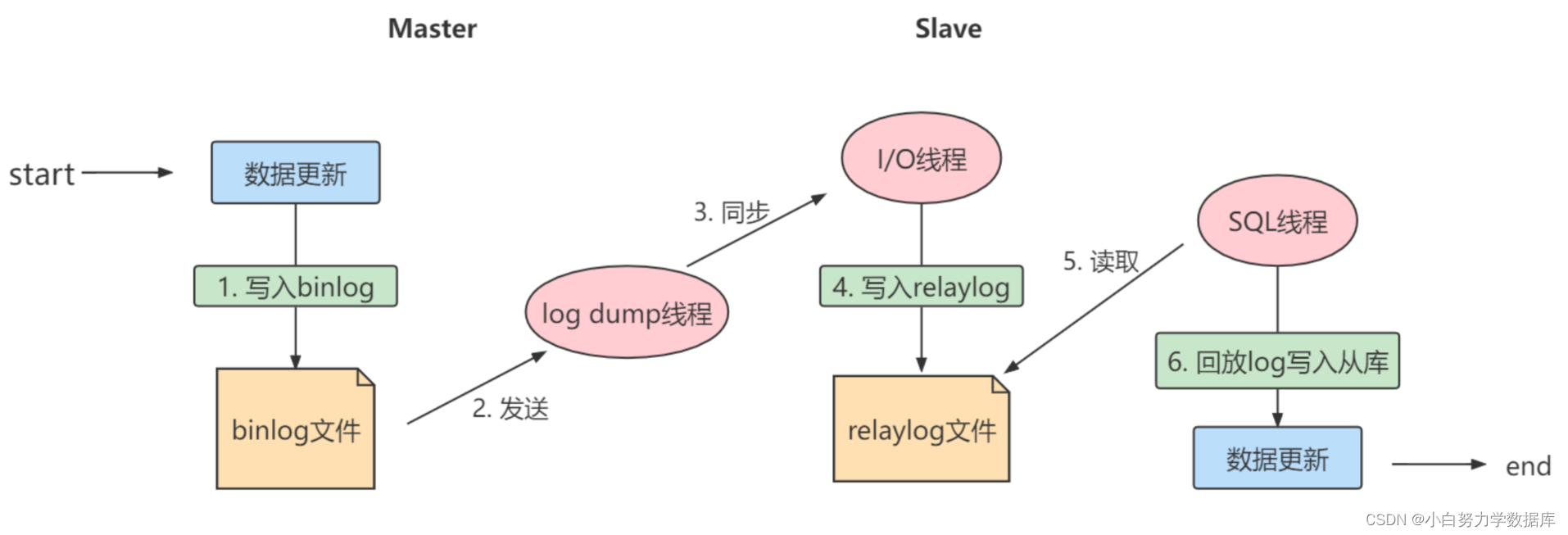
二进制日志转储线程(Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上加锁,读取完成之后,再将锁释放掉。
从库 I/O 线程会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
在这里插入图片描述
注意: 不是所有版本的MySQL都默认开启服务器的二进制日志。在进行主从同步的时候,我们需要先检查服务器是否已经开启了二进制日志。 除非特殊指定,默认情况下从服务器会执行所有主服务器中保存的事件。也可以通过配置,使从服务器执行特定的事件。
复制三步骤
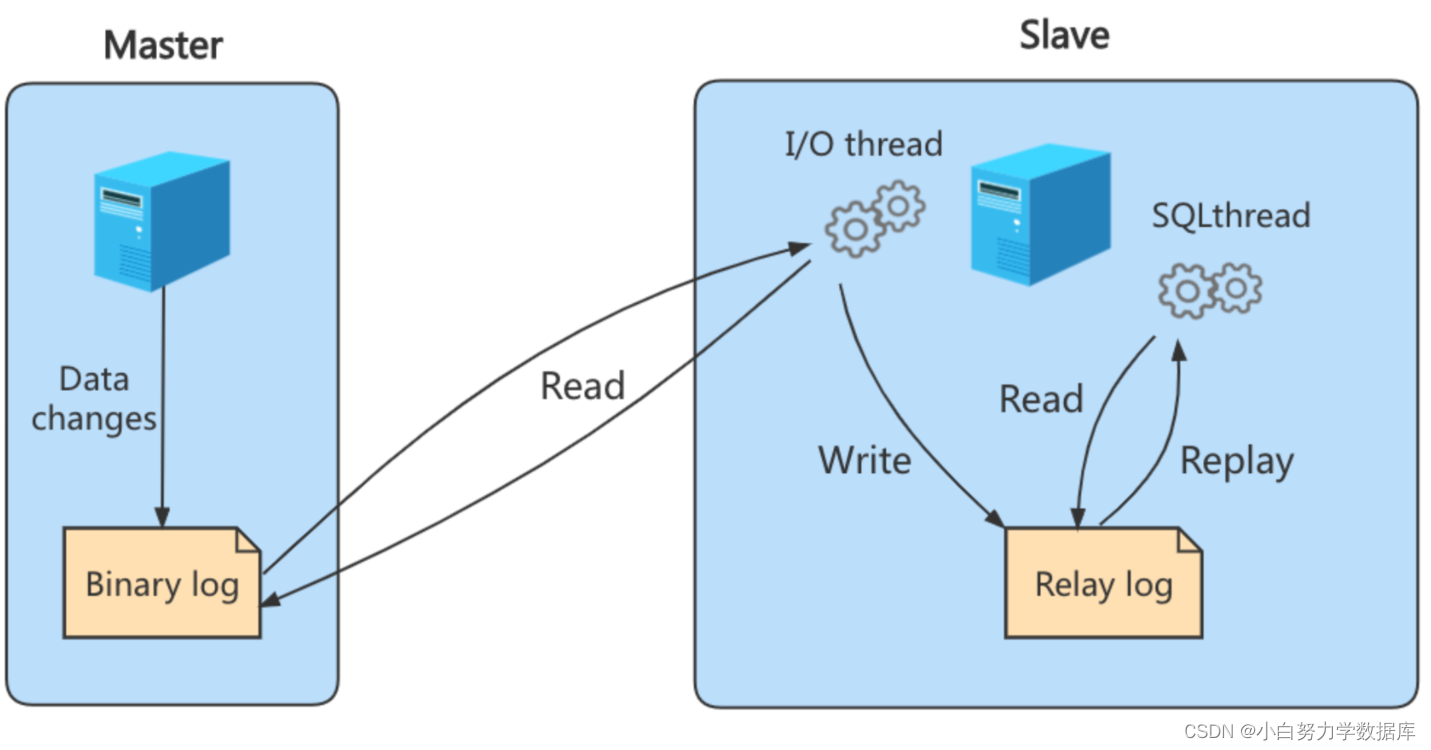
步骤 1 :Master将写操作记录到二进制日志(binlog)。
步骤 2 :Slave将Master的binary log events拷贝到它的中继日志(relay log);
步骤 3 :Slave重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的,而且重启后从接入点开始复制。
复制的问题
复制的最大问题:延时
每个Slave只有一个Master
每个Slave只能有一个唯一的服务器ID
每个Master可以有多个Slave
这里以GreatSQL为例详见文章主从复制构建
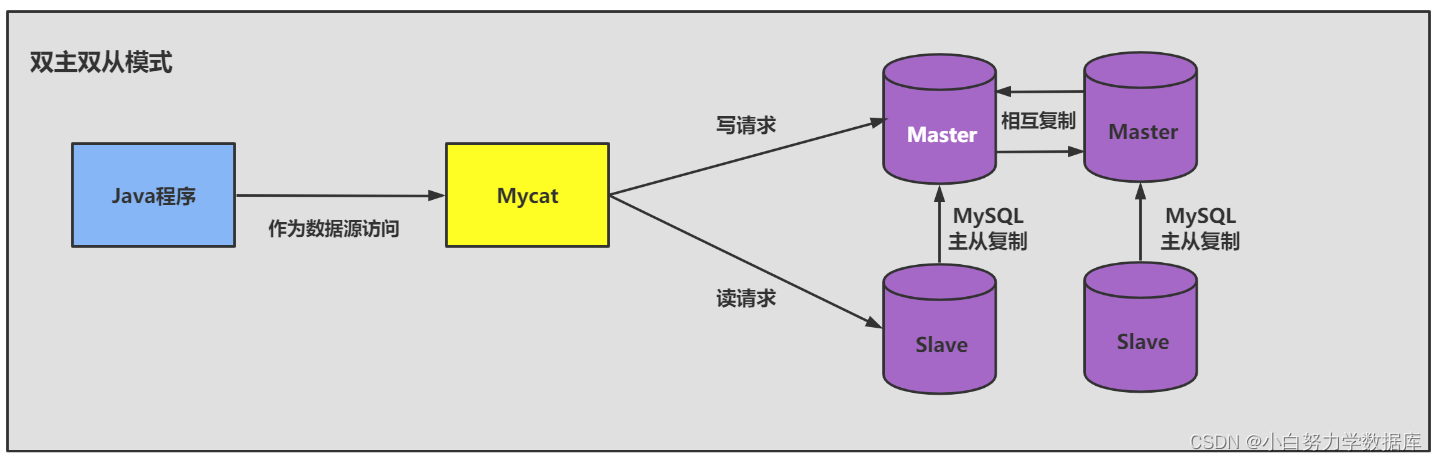
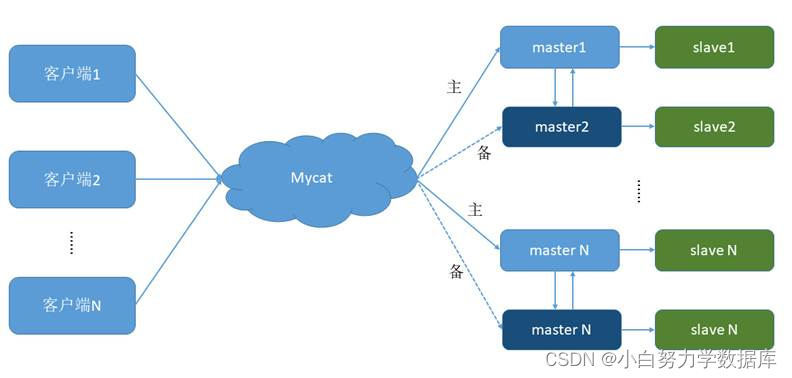
主从同步的要求:
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在主从延迟(比如 500 ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。
导致主从延迟的时间点主要包括以下三个:
在网络正常的时候,日志从主库传给从库所需的时间是很短的,即T 2 - T 1 的值是非常小的。即,网络正常情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。 造成原因:
1 、从库的机器性能比主库要差
2 、从库的压力大
3 、大事务的执行
若想要减少主从延迟的时间,可以采取下面的办法:
如果操作的数据存储在同一个数据库中,那么对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况。但这时从库的作用就是备份,并没有起到读写分离,分担主库读压力的作用。
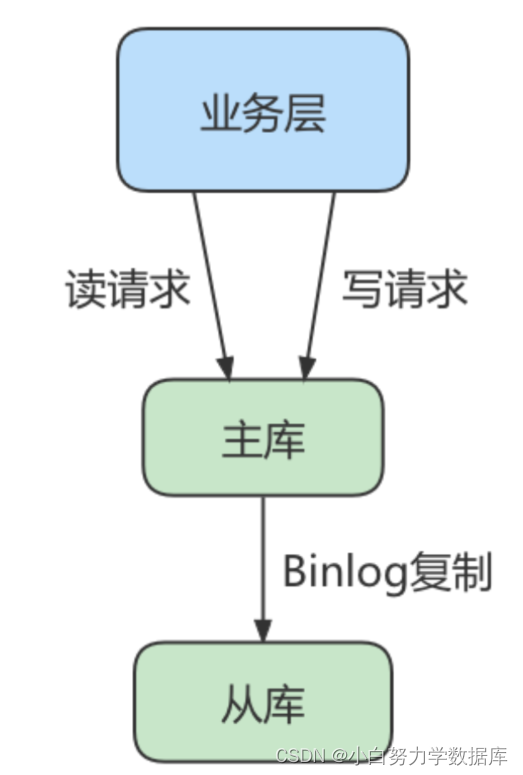
读写分离情况下,解决主从同步中数据不一致的问题, 就是解决主从之间数据复制方式的问题,如果按照数据一致性从弱到强来进行划分,有以下 3 种复制方式。
异步模式就是客户端提交COMMIT之后不需要等从库返回任何结果,而是直接将结果返回给客户端,这样做的好处是不会影响主库写的效率,但可能会存在主库宕机,而Binlog还没有同步到从库的情况,也就是此时的主库和从库数据不一致。这时候从从库中选择一个作为新主,那么新主则可能缺少原来主服务器中已提交的事务。所以,这种复制模式下的数据一致性是最弱的。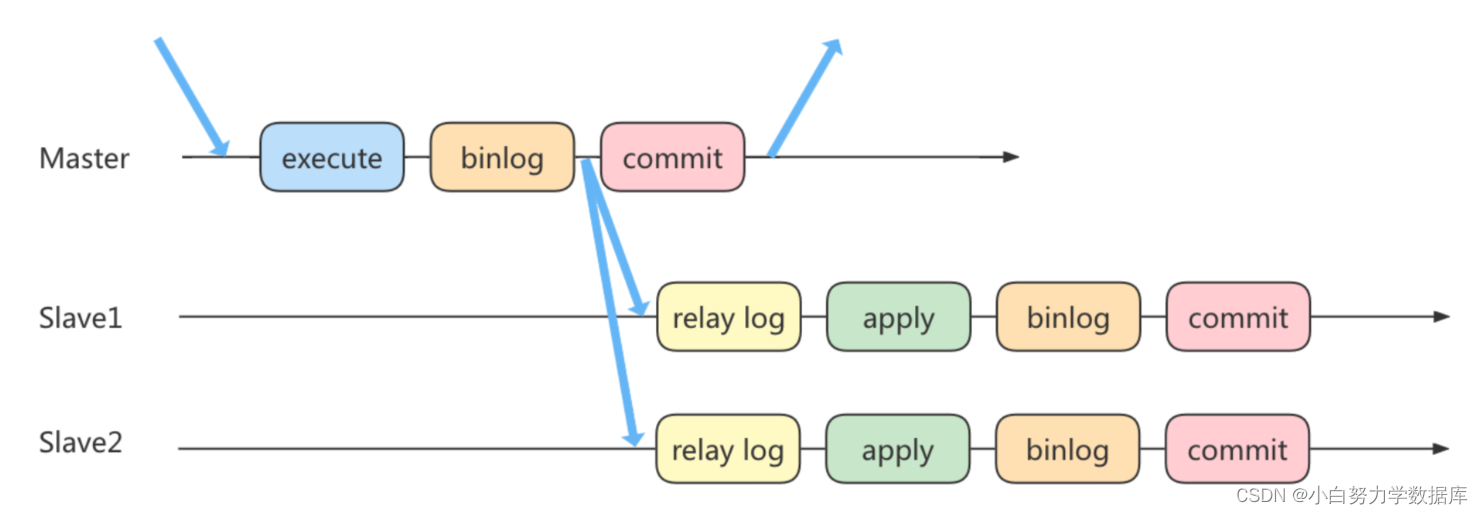
MySQL5.5版本之后开始支持半同步复制的方式。原理是在客户端提交COMMIT之后不直接将结果返回给客户端,而是等待至少有一个从库接收到了Binlog,并且写入到中继日志中,再返回给客户端。
这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
在MySQL5.7版本中还增加了一个rpl_semi_sync_master_wait_for_slave_count参数,可以对应答的从库数量进行设置,默认为1,也就是说只要有1个从库进行了响应,就可以返回给客户端。如果将这个参数调大,可以提升数据一致性的强度,但也会增加主库等待从库响应的时间。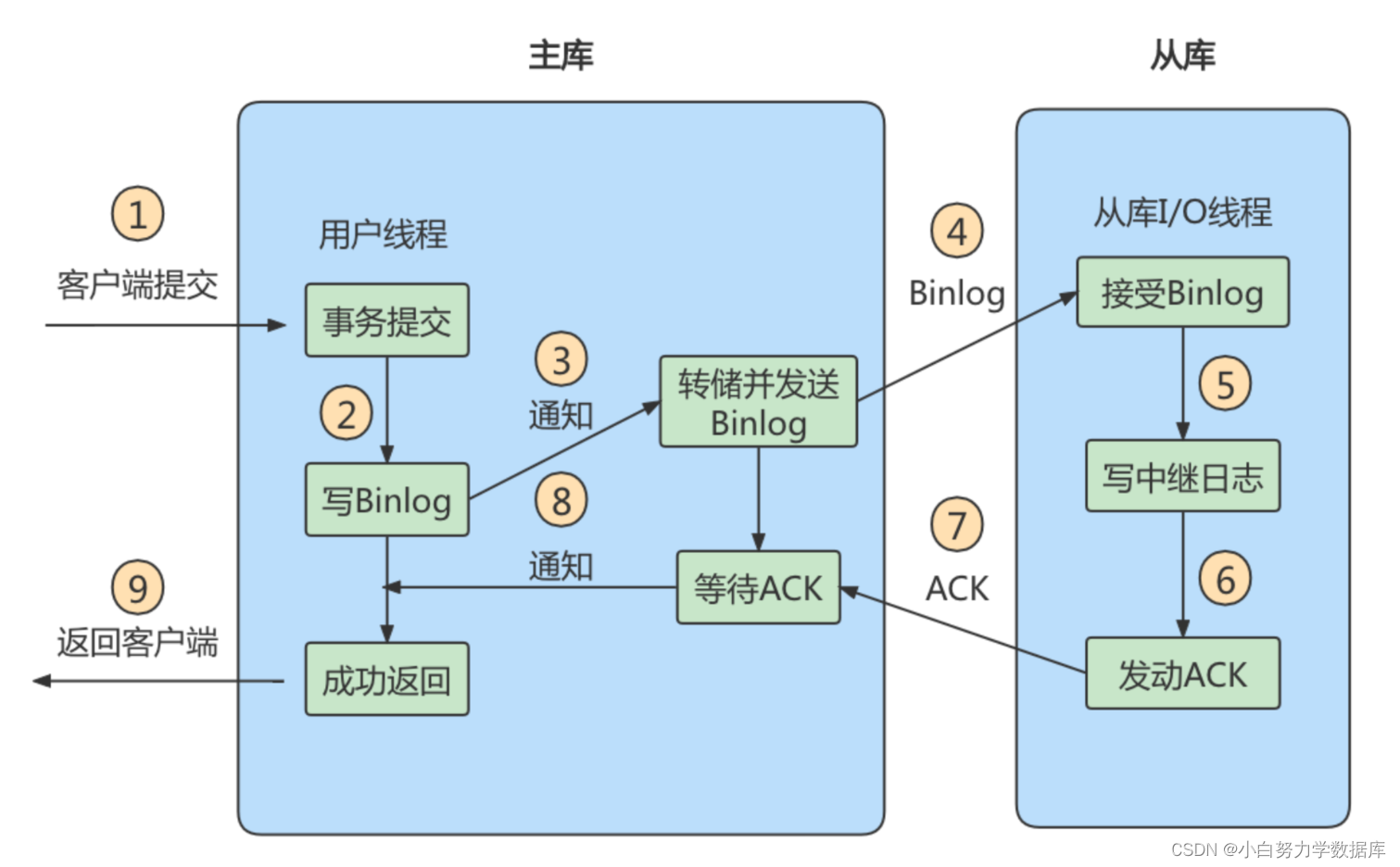
异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景,比如金融领域。MGR 很好地弥补了这两种复制模式的不足。
组复制技术,简称 MGR(MySQL Group Replication)。是 MySQL 在 5.7.17 版本中推出的一种新的数据复制技术,这种复制技术是基于 Paxos 协议的状态机复制。
MGR 是如何工作的
首先我们将多个节点共同组成一个复制组,在执行读写(RW)事务的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对只读(RO)事务则不需要经过组内同意,直接 COMMIT 即可。
在一个复制组内有多个节点组成,它们各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。
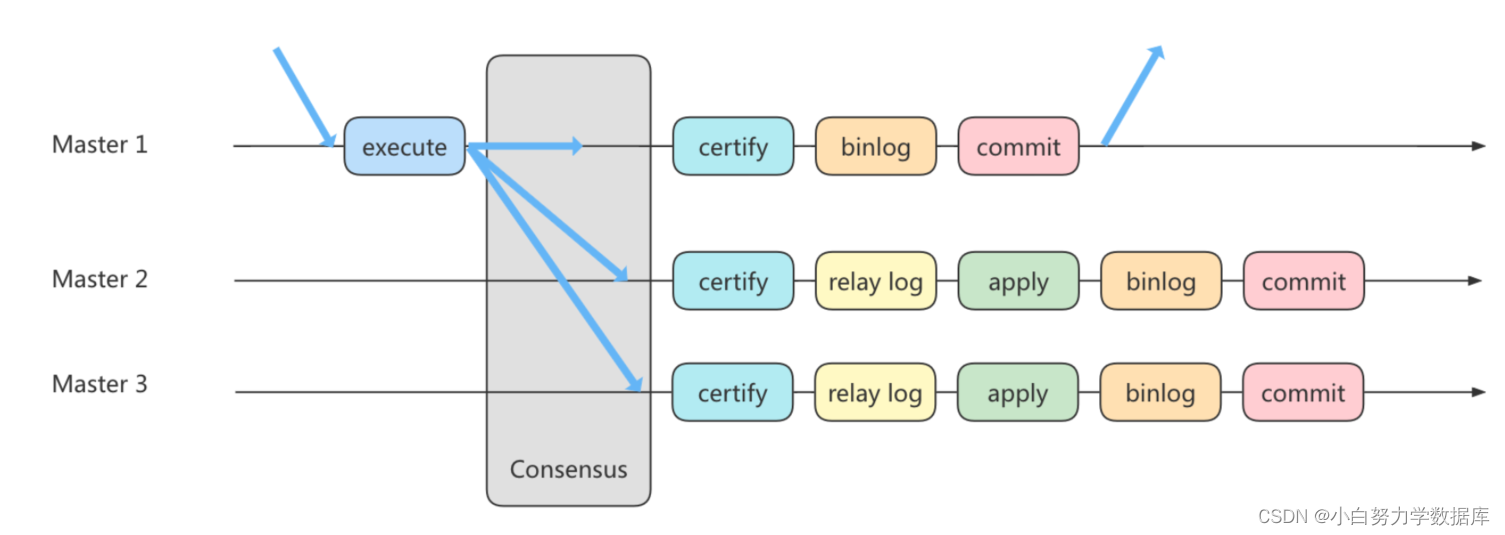
MGR 将 MySQL 带入了数据强一致性的时代,是一个划时代的创新,其中一个重要的原因就是MGR 是基于 Paxos 协议的。Paxos 算法是由 2013 年的图灵奖获得者 Leslie Lamport 于 1990 年提出的,有关这个算法的决策机制可以搜一下。事实上,Paxos 算法提出来之后就作为分布式一致性算法被广泛应用,比如Apache 的 ZooKeeper 也是基于 Paxos 实现的。
在主从架构的配置中,如果想要采取读写分离的策略,我们可以自己编写程序,也可以通过第三方的中间件来实现。
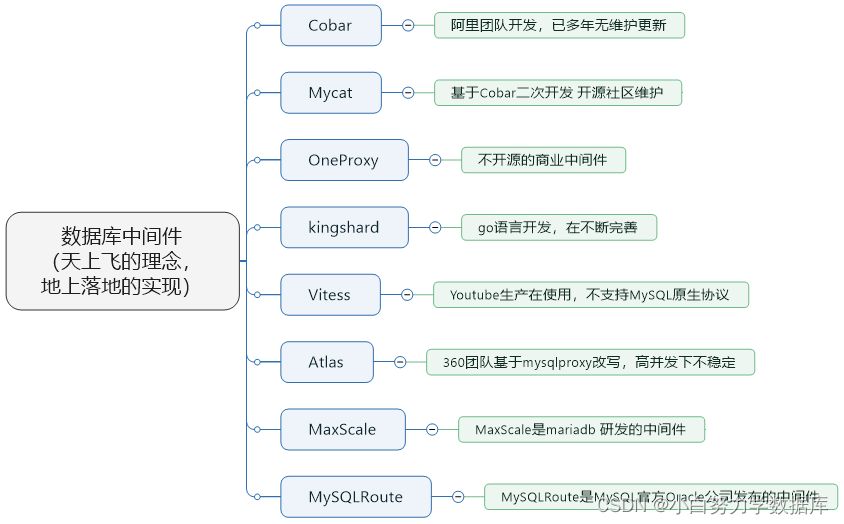
① Cobar属于阿里B2B事业群,始于 2008 年,在阿里服役 3 年多,接管3000+个MySQL数据库的schema,集群日处理在线SQL请求 50 亿次以上。由于Cobar发起人的离职,Cobar停止维护。
② Mycat是开源社区在阿里cobar基础上进行二次开发,解决了cobar存在的问题,并且加入了许多新的功能在其中。青出于蓝而胜于蓝。
③ OneProxy基于MySQL官方的proxy思想利用c语言进行开发的,OneProxy是一款商业收费的中间件。舍弃了一些功能,专注在性能和稳定性上。
④ kingshard由小团队用go语言开发,还需要发展,需要不断完善。
⑤ Vitess是Youtube生产在使用,架构很复杂。不支持MySQL原生协议,使用需要大量改造成本。
⑥ Atlas是 360 团队基于mysql proxy改写,功能还需完善,高并发下不稳定。
⑦ MaxScale是mariadb(MySQL原作者维护的一个版本) 研发的中间件
⑧ MySQLRoute是MySQL官方Oracle公司发布的中间件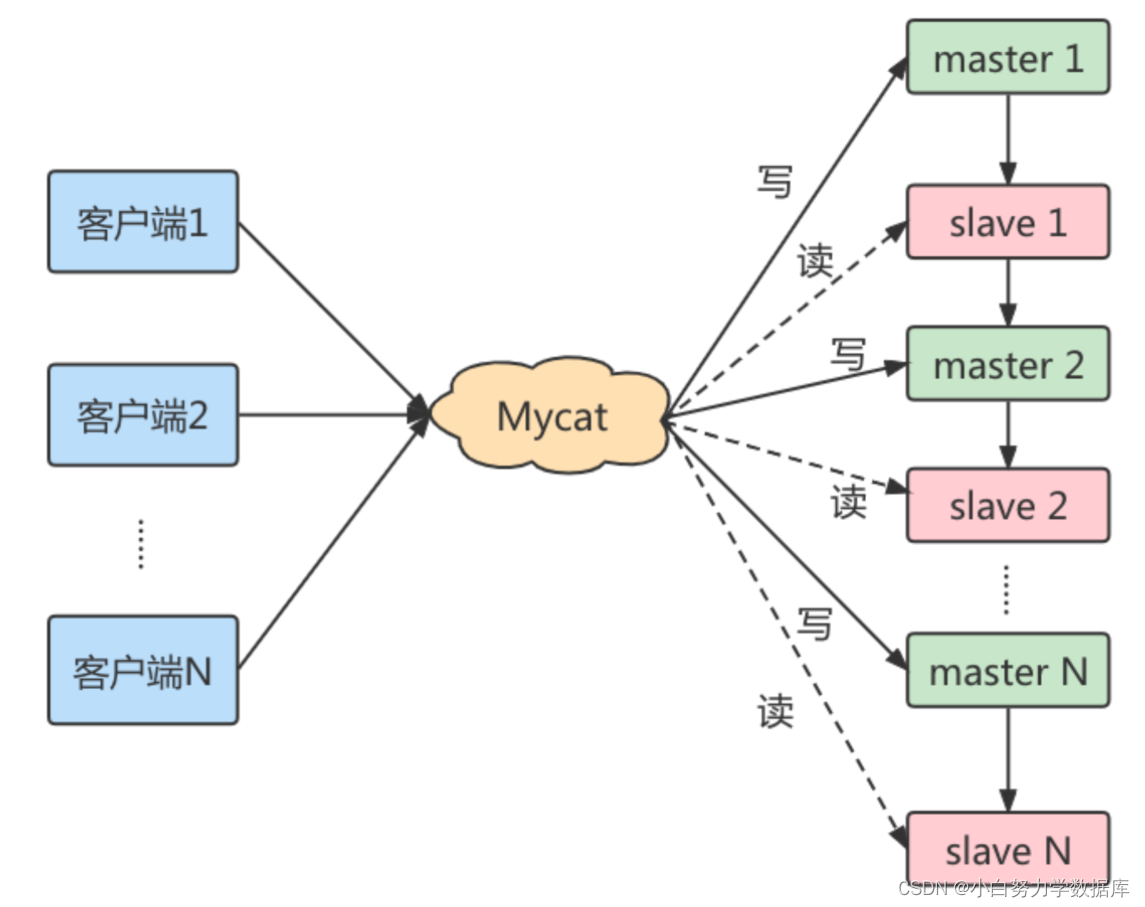
主备切换: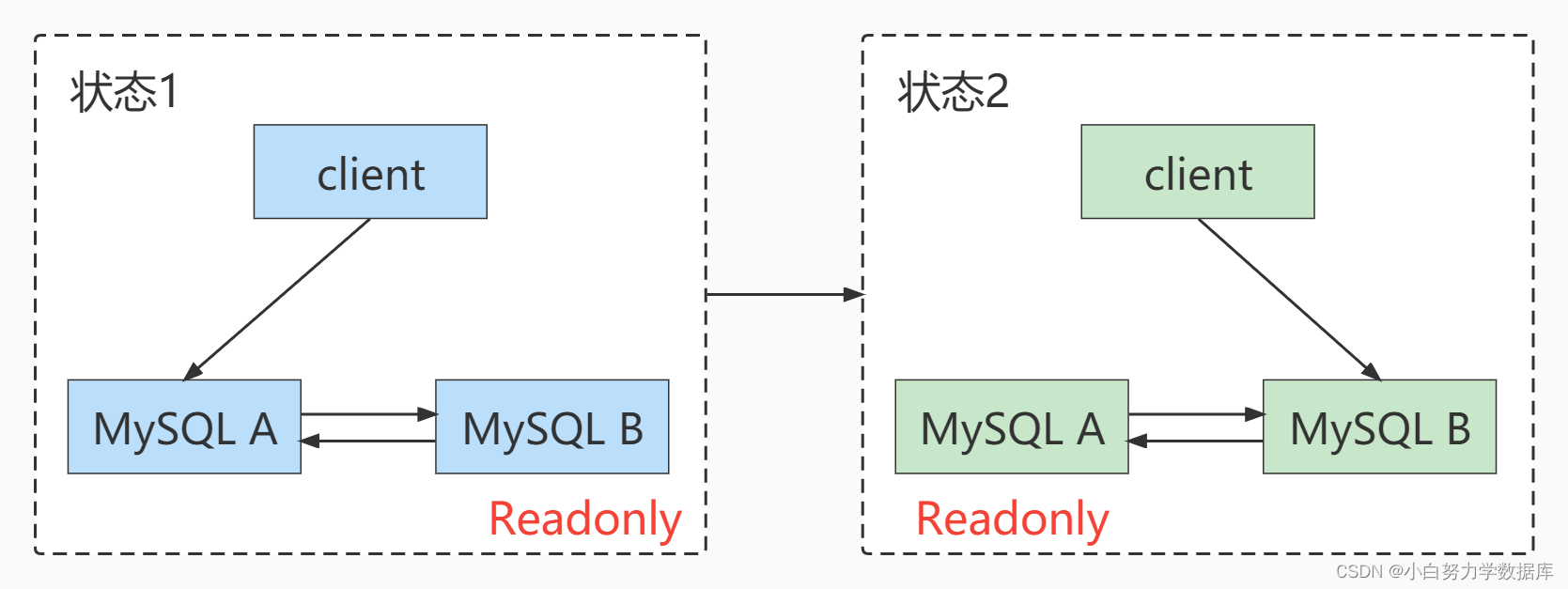
合作电话:010-64087828
社区邮箱:greatsql@greatdb.com


