||
注意:与单行函数不同的是,聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
求平均值和求和
==AVG和SUM再计算时候会过滤空值==
举例用表salary;salary是工资。
mysql> desc salary;+--------+--------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+--------+--------------+------+-----+---------+-------+| userid | int(11) | YES | | NULL | || salary | decimal(9,2) | YES | | NULL | |+--------+--------------+------+-----+---------+-------+2 rows in set (0.01 sec)mysql> select * from salary;+--------+---------+| userid | salary |+--------+---------+| 1 | 1000.00 || 2 | 2000.00 || 3 | 3000.00 || 4 | 4000.00 || 5 | 5000.00 || 1 | NULL |+--------+---------+6 rows in set (0.00 sec)#AVG和SUM使用mysql> select AVG(salary),SUM(salary)from salary;+-------------+-------------+| AVG(salary) | SUM(salary) |+-------------+-------------+| 3000.000000 | 15000.00 |+-------------+-------------+1 row in set (0.00 sec)最大值和最小值
==适用于数值类型,字符串类型,时间日期类型的字段或变量==
mysql> select MAX(salary),MIN(salary) from salary;+-------------+-------------+| MAX(salary) | MIN(salary) |+-------------+-------------+| 5000.00 | 1000.00 |+-------------+-------------+1 row in set (0.00 sec)计数作用
mysql> select COUNT(userid) from salary;+---------------+| COUNT(userid) |+---------------+| 6 |+---------------+1 row in set (0.00 sec)count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
查询各个部门的平均工资
SELECT department_id,AVG(salary)FROM employessGROUP BY department_id;SELECT 中出现的非组函数的字段必须声明在GROUP BY中,反之GROUP BY中声明的字段可以不出现在SELECT中
例如:
正确SELECT department_id,job_id,AVG(salary)FROM employeesGROUP BY department_id,job_id;错误-SELECT中出现的非组函数的字段没有全部声明在GROUP BY 中-SELECT department_id,job_id,AVG(salary)FROM employeesGROUP BY department_id;GROUP BY声明在FROM后面 WHERE后面 ORDER BY 前面 LIMIT前面
mysql> SELECT userid,AVG(salary) FROM salary GROUP BY userid WITH ROLLUP;+--------+-------------+| userid | AVG(salary) |+--------+-------------+| 1 | 1000.000000 || 2 | 2000.000000 || 3 | 3000.000000 || 4 | 4000.000000 || 5 | 5000.000000 || NULL | 3000.000000 |+--------+-------------+6 rows in set (0.00 sec)注意:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
是用来过滤数据的
错误的,因为WHERE中使用了MAX聚合函数,所以只能使用HAVINGSELECT userid,MAX(salary)FROM salaryWHERE MAX(salary) > 1000;GROUP BY userid;那我们就把WHERE换成HAVING试试,结果发现还是出错
错误的,因为HAVING要放在GROUP BY后面SELECT userid,MAX(salary)FROM salaryHAVING MAX(salary) > 1000;GROUP BY userid;最后修改
mysql> SELECT userid,MAX(salary) -> FROM salary -> GROUP BY userid -> HAVING MAX(salary) > 1000;+--------+-------------+| userid | MAX(salary) |+--------+-------------+| 2 | 2000.00 || 3 | 3000.00 || 4 | 4000.00 || 5 | 5000.00 |+--------+-------------+4 rows in set (0.00 sec)开发中,我们使用 HAVING 的前提是SQL中使用了 GROUP BY
再举一个例子
查询部门id为1,2,3这3个部门中最高工资比2500高的部门信息:
mysql> select userid,MAX(salary) FROM salary -> WHERE userid IN (1,2,3) -> GROUP BY userid -> HAVING MAX(salary)>2500;+--------+-------------+| userid | MAX(salary) |+--------+-------------+| 3 | 3000.00 |+--------+-------------+1 row in set (0.00 sec)方式2:mysql> select userid,MAX(salary) FROM salary -> GROUP BY userid -> HAVING MAX(salary)>2500 AND userid IN (1,2,3);+--------+-------------+| userid | MAX(salary) |+--------+-------------+| 3 | 3000.00 |+--------+-------------+1 row in set (0.00 sec)方式1的执行效率高于方式2
结论:
WHERE与HAVING对比
SQL92语法:SELECT ...,...,... (存在聚合函数)FROM ...,...,...WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件GROUP BY ...,...,...(分组)HAVING 包含聚合函数的过滤条件ORDER BY ...,... (ASC升序 / DESC降序)LIMIT ...,...(分页)SQL99语法SELECT ...,...,... (存在聚合函数)FROM ...(LEFT / RIGHT)JOIN...ON 多表的连接条件(LEFT / RIGHT)JOIN....ON...(左连接/右连接)WHERE 不包含聚合函数的过滤条件GROUP BY ...,...,...(分组)HAVING 包含聚合函数的过滤条件ORDER BY ...,... (ASC升序 / DESC降序)LIMIT ...,...(分页)FROM 表,表—>ON 限制连接条件—> 是否是LEET / RINGHT JOIN —> WHERE —> GROUP BY —> HAVING —>SELECT —>DISTINCT —> ORDER BY —> LIMIT
先找表,再根据连接条件进行多表连接,(左或右外连接),WHERE筛选,分组,HAVING筛选,SELECT查询,去重,排序,分页
==过滤条件越靠前,执行效率越高,所以WHERE比HAVING效率高==
==在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。我们最终看到的是经过筛选得到的结果集。==
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
1.首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
2.通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
3.添加外部行。如果我们使用的是左连接、右连接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表vt1 ,就可以在此基础上再进行WHERE 阶段 。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表vt2。
然后进入第三步和第四步,也就是 GROUP和 HAVING 阶段 。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表vt3和vt4 。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT和 DISTINCT阶段 。
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1 和vt5-2 。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY阶段 ,得到虚拟表vt6 。
最后在 vt6 的基础上,取出指定行的记录,也就是LIMIT 阶段 ,得到最终的结果,对应的是虚拟表vt7。
当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
图解: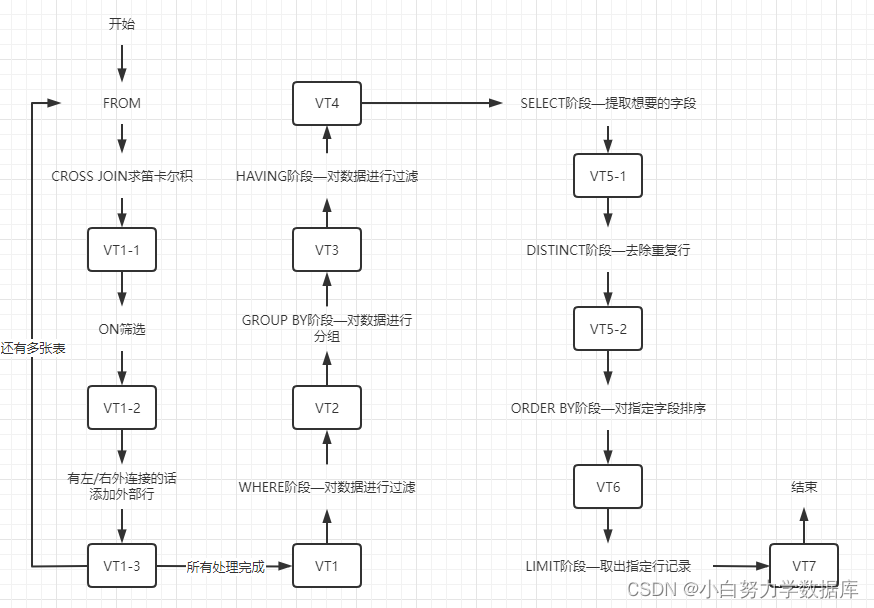
合作电话:010-64087828
社区邮箱:greatsql@greatdb.com


