||
GreatSQL合并Percona-Server 8.0.30的Beta版测试中,QA报了一个crash的bug:
########### bug list ##########
benchmarksql加载1000仓数据时,数据库实例发生coredump。
core堆栈信息如下:
#0 0x00007f51315a39d1 in pthread_kill () from /lib64/libpthread.so.0
#1 0x00000000013258cd in handle_fatal_signal () at /src/sql/signal_handler.cc:228
#2
#3 0x0000000001339244 in mem_root_deque::push_back () at /src/include/mem_root_deque.h:182
#4 0x0000000001364a16 in push_back () at /src/sql/parse_tree_helpers.h:126
#5 MYSQLparse(THD*, Parse_tree_root**) () at /src/sql/sql_yacc.yy:13506
#6 0x000000000103a595 in THD::sql_parser () at /src/sql/sql_class.cc:3287
#7 0x00000000010d0e37 in parse_sql () at /src/sql/sql_parse.cc:7353
#8 0x00000000010d61bd in dispatch_sql_command () at /src/sql/sql_parse.cc:5399
#9 0x00000000010d78d0 in dispatch_command () at /src/sql/sql_parse.cc:2052
#10 0x00000000010d9a12 in do_command () at /src/sql/sql_parse.cc:1424
#11 0x00000000013159f8 in handle_connection () at /src/sql/conn_handler/connection_handler_per_thread.cc:308
#12 0x00000000027db225 in pfs_spawn_thread () at /src/storage/perfschema/pfs.cc:2943
#13 0x00007f513159edd5 in start_thread () from /lib64/libpthread.so.0
#14 0x00007f512ffa9ead in clone () from /lib64/libc.so.6
core文件在测试服务器xxx.xxx.xxx.xxx的xxx目录,能够稳定复现crash。通常有core文件的话定位bug不算太难。
第一时间使用GDB打开core文件,切到相应函数调用栈尝试打印关键变量的信息:
但无论尝试任何变量,使用gdb打印时均会报:“gdb: No symbol "xxx" in current context”。
最初怀疑是GDB版本过低,安装devtoolset-11并使用高版本GDB后问题依旧。检查出包时的编译记录,发现cmake后,"CMAKE_CXX_FLAGS_RELWITHDEBINFO"后的编译选项多了"-g1"。
CMAKE_CXX_FLAGS_RELWITHDEBINFO: -DNDEBUG -D_FORTIFY_SOURCE=2 -ffunction-sections -fdata-sections -O2 -g -DNDEBUG -g1原因是新版本多了编译选项“MINIMAL_RELWITHDEBINFO”,该选项在打包时自动开启。
向打包脚本添加"-DMINIMAL_RELWITHDEBINFO=OFF"后重新打包。经验证,此时GDB能够attach到新部署的数据库实例并打印变量。
经上述尝试后,开始基于原始环境复现问题并分析core文件中的异常内存数据。
由于crash时的位置不同,选择较早crash时的core文件进行分析,堆栈如下(发生在parser阶段):
#0 0x00007f51315a39d1 in pthread_kill () from /lib64/libpthread.so.0
#1 0x00000000013258cd in handle_fatal_signal () at /src/sql/signal_handler.cc:228
#2
#3 0x0000000001339244 in mem_root_deque::push_back () at /src/include/mem_root_deque.h:182
#4 0x0000000001364a16 in push_back () at /src/sql/parse_tree_helpers.h:126
#5 MYSQLparse(THD*, Parse_tree_root**) () at /src/sql/sql_yacc.yy:13506
#6 0x000000000103a595 in THD::sql_parser () at /src/sql/sql_class.cc:3287
#7 0x00000000010d0e37 in parse_sql () at /src/sql/sql_parse.cc:7353
#8 0x00000000010d61bd in dispatch_sql_command () at /src/sql/sql_parse.cc:5399
#9 0x00000000010d78d0 in dispatch_command () at /src/sql/sql_parse.cc:2052
#10 0x00000000010d9a12 in do_command () at /src/sql/sql_parse.cc:1424
#11 0x00000000013159f8 in handle_connection () at /src/sql/conn_handler/connection_handler_per_thread.cc:308
#12 0x00000000027db225 in pfs_spawn_thread () at /src/storage/perfschema/pfs.cc:2943
#13 0x00007f513159edd5 in start_thread () from /lib64/libpthread.so.0
#14 0x00007f512ffa9ead in clone () from /lib64/libc.so.6切到"#3",打印mem_root_deque<Item*>对象的内容:
"INSERT INTO bmsql_xxxx ..."。切到"#7",“p parser_state->m_lip->m_buf_length”输出原始sql语句的长度,将gdb定向到log文件,调整print element足够大后执行“p parser_state->m_lip->m_buf”,导出原始sql语句到log文件。 此时可发现异常内存的内容为当前语句的头部。
由于“mem_root_deque”使用的内存是从当前THD->mem_root分配的,基本可判断是当前session的"thd->mem_root"分配异常。即已分配出去的内存被重新分配给其它对象,最终造成coredump。
以上信息还不够准确定位问题。为进一步缩小排查范围,尝试将benchmarksql在load数据期间发送的语句记录到general_log,将general_log中的语句导出到文本,使用文本中固定的语句尝试触发crash并验证crash时间点是否一致。
重启数据库实例、清理并重建database、开启general_log、启动benchmarksql导入。一段时间后数据库crash,一切按预期进行。
打开general_log,找benchmarksql对应的session时发现general_log多了部分内容,每隔几秒执行一次。
2023-02-12T09:08:43.665421+08:00 243 Connect greatsql@***.**.***.*** on using TCP/IP
2023-02-12T09:08:43.666014+08:00 243 Query SET AUTOCOMMIT = 0
2023-02-12T09:08:43.666791+08:00 243 Query SHOW GLOBAL STATUS
2023-02-12T09:08:43.698693+08:00 243 Query show variables
2023-02-12T09:08:43.739684+08:00 243 Query select count(*) from information_schema.innodb_trx where now()-trx_started>10
2023-02-12T09:08:43.740640+08:00 243 Query select count(*) from information_schema.innodb_trx where now()-trx_started>60
2023-02-12T09:08:43.741376+08:00 243 Query select count(*) from information_schema.innodb_trx where now()-trx_started>180
2023-02-12T09:08:43.742095+08:00 243 Query select count(*) from information_schema.innodb_trx where now()-trx_started>600
2023-02-12T09:08:43.742751+08:00 243 Query show engine innodb status
2023-02-12T09:08:43.744324+08:00 243 Query select round(innodb_buffer_pool_read_requests / (innodb_buffer_pool_read_requests + innodb_buffer_pool_reads) * 100,2) FROM (SELECT max(CASE VARIABLE_NAME WHEN 'innodb_buffer_pool_read_requests' THEN VARIABLE_VALUE ELSE 0 END) AS innodb_buffer_pool_read_requests, max(CASE VARIABLE_NAME WHEN 'innodb_buffer_pool_reads' THEN VARIABLE_VALUE ELSE 0 END) AS innodb_buffer_pool_reads FROM performance_schema.global_status) t
2023-02-12T09:08:43.747029+08:00 243 Query SHOW SLAVE STATUS
2023-02-12T09:08:43.758254+08:00 243 Query SHOW WARNINGS
2023-02-12T09:08:43.759621+08:00 243 Query show binary logs
2023-02-12T09:08:43.760013+08:00 243 Query select count(1) from information_schema.INNODB_TRX
2023-02-12T09:08:43.760676+08:00 243 Query select count(1) from performance_schema.DATA_LOCK_WAITS
2023-02-12T09:08:43.761246+08:00 243 Query select count(1) from performance_schema.DATA_LOCKS
2023-02-12T09:08:43.761829+08:00 243 Query select count(1) from information_schema.tables where engine='MEMORY'
2023-02-12T09:08:43.765503+08:00 243 Query select count(1) from information_schema.tables where engine='InnoDB'
2023-02-12T09:08:43.770064+08:00 243 Query select count(1) from information_schema.tables where engine='MyISAM'
2023-02-12T09:08:43.770126+08:00 244 Quit
2023-02-12T09:08:43.772994+08:00 243 Query select count(1) from information_schema.tables where engine='CSV'
2023-02-12T09:08:43.775934+08:00 243 Query select count(1) from information_schema.tables where engine='PERFORMANCE_SCHEMA'
2023-02-12T09:08:43.783303+08:00 243 Query show variables like '%semi%'
2023-02-12T09:08:43.787773+08:00 243 Query show status like '%semi%'
2023-02-12T09:08:43.790204+08:00 243 Query select rgms.COUNT_TRANSACTIONS_IN_QUEUE from performance_schema.replication_group_members rgm ,performance_schema.replication_group_member_stats rgms where rgm.CHANNEL_NAME=rgms.CHANNEL_NAME and rgm.MEMBER_ID=rgms.MEMBER_ID and rgm.MEMBER_HOST='***.**.***.***' and rgm.MEMBER_PORT='1957'
2023-02-12T09:08:43.790947+08:00 243 Query select MEMBER_STATE,MEMBER_ROLE from performance_schema.replication_group_members where MEMBER_HOST='***.**.***.***' and MEMBER_PORT='1957'
2023-02-12T09:08:43.794132+08:00 243 Query select max( if(LAST_APPLIED_TRANSACTION <>'', timestampdiff(MICROSECOND,LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP,LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP) div 1000,0)) 'max_worker_latency' from performance_schema.replication_applier_status_by_worker where SERVICE_STATE='ON' and CHANNEL_NAME='group_replication_applier'
2023-02-12T09:08:43.794800+08:00 243 Query select max(count_transactions_remote_in_applier_queue) from performance_schema.replication_group_member_stats
2023-02-12T09:08:43.795266+08:00 243 Quit看到多的这部分内容,心里一震,原来QA部署的数据库实例会被平台纳管。 莫非是这些语句导致benchmarksql导入数据时crash?
写了个简单脚本,循环向数据库实例发送指定文件中的sql语句
file repeat_sql_file.sh:
#!/bin/bash
for ((i=1;i<=1000000000;i++)) ;
do
usleep 100
greatsql -h***.**.***.*** -ugreatsql -p123456 -P1957 < $1
done再将general log中的语句取出到文件monit.sql,执行命令"file repeat_sql_file.sh monit.sql"。然后启动benchmarksql导入数据。
仅仅过了15秒,数据库实例crash。
接下来要找到肇事sql。采用二分查找法先注释一半内容逐步验证,重复几次后将肇事语句锁定到了DBA最常用的一条语句:
show engine innodb status;下载Percona-8.0.30官方源码并按上述步骤编译安装部署后,重现了crash!
继续验证MySQL官方的8.0.30,发现该crash没有触发。
既然已明确是Percona-Server的bug,那就先到MySQL和Percona官网看新版本release note有没有和"show engine innodb status"相关的bugfix。
首先是Percona-8.0.31,未看到相关bugfix说明,只看到一个从库crash的bugfix。
(https://docs.percona.com/percona-server/8.0/release-notes/8.0.31-23.html#bug-fixes)

但release notes list中看到多了一个8.0.30-update:其中有一个bugfix涉及到"show engine innodb status"
(https://docs.percona.com/percona-server/8.0/release-notes/8.0.30-22.upd.html#bug-fixes)

定位Percona 8.0.30 PS-8351相关patch,可看到Percona修改了一些代码,而这部分代码在MySQL 8.0.30上是未被修改的:
430 char *thd_security_context(MYSQL_THD thd, char *buffer, size_t length,
431 size_t max_query_len) {
487 LEX_STRING truncated_query = {nullptr, 0}; // 这里是Percona引入的
488 if (len < thd->query().length &&
489 !thd->convert_string(&truncated_query, thd->charset(), thd->query().str,
490 len, thd->charset())) {
491 str.append(truncated_query.str, truncated_query.length);
492 } else {
493 // In case of error or not trimming, fall back to the original behavior
494 str.append(thd->query().str, len);
........其调用逻辑为:
| > innodb_show_status
| | > srv_printf_innodb_monitor
| | | > srv_printf_locks_and_transactions
| | | | > lock_print_info_all_transactions
| | | | | > lock_trx_print_wait_and_mvcc_state
| | | | | | > trx_print_latched
| | | | | | | > trx_print_low
| | | | | | | | > innobase_mysql_print_thd
| | | | | | | | | > thd_security_context // MySQL原始代码不会调用convert_string
| | | | | | | | | | > THD::convert_string而在trx_print_low中:很明显作为参数传递下去的"trx->mysql_thd"归属于实例中其它活跃的session,而不是归属于当前执行"show engine innodb status"的session
void trx_print_low() {
.....
if (trx_state != TRX_STATE_NOT_STARTED && trx->mysql_thd != nullptr) {
innobase_mysql_print_thd(f, trx->mysql_thd,
static_cast(max_query_len));
}
}继续看convert_string:执行"show engine innodb status"的session使用了其它session的mem_root开辟了内存空间。
bool THD::convert_string(){
size_t new_length = to_cs->mbmaxlen * from_length;
if (!(to->str = (char *)alloc(new_length + 1))) {
to->length = 0; // Safety fix
return true; // EOM
}
......
}
// alloc实际调用的是THD的父类成员函数Query_arena::alloc(),代码为
class Query_arena {
....
void *alloc(size_t size) { return mem_root->Alloc(size); }
....
};因此,一旦“thd->convert_string()”使用thd->memroot申请内存,就会出现两个线程并发操作thd->memroot。由于对同一mem_root的操作不是线程安全的,两个线程分配的内存空间可能存在重叠。
随着"show engine innodb status"线程的运行,重叠内存区域的内容可能会被填上部分原始sql语句。回顾上文中打印mem_root_deque<Item*>对象的内存内容,其尾部也确实包含了原始sql语句的开头。
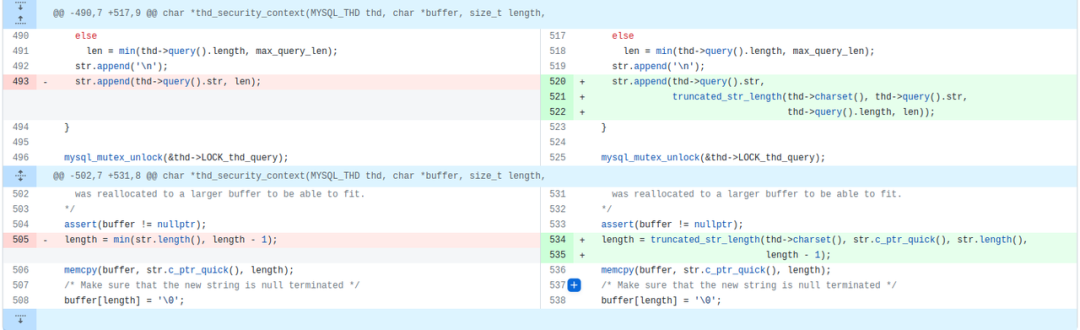
目前MySQL-8.0.32版本的release note中已有相关的patch:

从commit信息看,该commit来自Percona。
Truncating a message at a fixed length might leave
a partial UTF-8 character at the end of a truncated message.
This patch makes sure, that a truncation doesn't result
in such a "garbled" character.
Patch is based on contribution from Iwo Panowicz
Thanks to Iwo and Percona for this patch.
Change-Id: I5f8e6dce28608f432fbb4b77220e1a21049f510f解决了show engine innodb status乱码问题的同时,不再使用“convert_string()”。
合作电话:010-64087828
社区邮箱:greatsql@greatdb.com


