§ Redo Log(重做日志)
§ 什么是 Redo Log(重做日志)
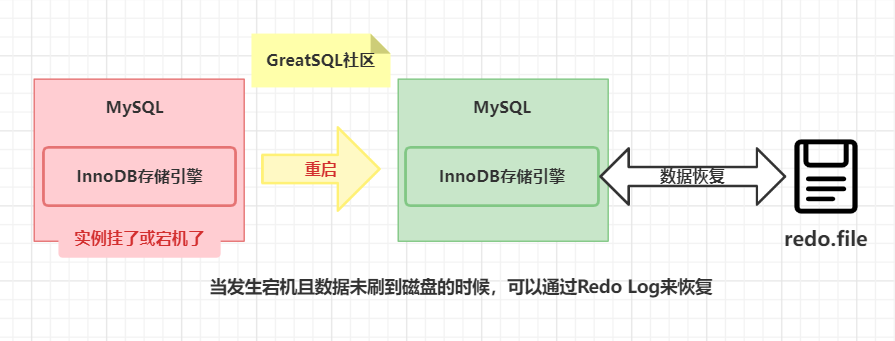
Redo Log(重做日志)是 InnoDB 中用于确保数据持久性和一致性的机制的关键组件。Redo Log 中记录所有修改数据的事务操作,这样即使在系统崩溃时也能通过重做日志进行恢复。
Redo Log 对 InnoDB 很重要,主要以下几点原因:
- 数据恢复:Redo Log 确保在系统崩溃后,可以恢复已提交但尚未写入磁盘的数据,确保数据完整性。
- 事务持久性:它记录了所有提交事务的修改,保证数据在事务提交后不会丢失。
- 性能提升:通过先写入 Redo Log(也就是 WAL,Write-Ahead Logging),再批量将事务数据合并写入磁盘,减少了频繁的磁盘 I/O 操作,大幅提高数据库性能。
没有 Redo Log,InnoDB 无法提供数据恢复和事务持久性保障,严重影响数据可靠性和数据库性能。
§ 配置 Redo Log
从 8.0.30 开始,只需要设置参数 innodb_redo_log_capacity 即可定义 Redo Log 总容量上限。
它支持在线动态修改并立即生效:
-- 修改 Redo Log 总容量为 8GB
SET GLOBAL innodb_redo_log_capacity = 8589934592;
2
调整 Redo Log 总容量后,需要先把 buffer pool 中的脏页刷新到磁盘中,再完成收缩或扩展;如果是把调小,则需要尽快刷脏页;如果是调大,则刷脏页的动作会慢一些。
也支持通过 my.cnf 修改,添加/修改下面内容即可,重启后即可生效:
[mysqld]
innodb_redo_log_capacity = 8G
2
当 innodb_redo_log_capacity 设置了,则不管 innodb_log_file_size 或 innodb_log_files_in_group 是否也设置了都不生效,Redo Log 总量以 innodb_redo_log_capacity 为准。
当 innodb_redo_log_capacity 未设置,并且 innodb_log_file_size 或 innodb_log_files_in_group 也都没设置时,则 Redo Log 总量等于 innodb_redo_log_capacity 的默认值,即 100MB。
当 innodb_redo_log_capacity 未设置,但 innodb_log_file_size 和 innodb_log_files_in_group 其中之一或二者设置了,则 Redo Log 总容量为 innodb_log_file_size \*innodb_log_files_in_group。
§ Redo Log 文件
Redo Log 文件存储在 #innodb_redo 目录下,而 #innodb_redo 目录默认位于 datadir 目录下,除非额外设置了 innodb_log_group_home_dir 参数。
Redo Log 有两种类型:使用中(ordinary)、备用的(spare)。InnoDB 会尝试维护 32 个 Redo Log 文件,每个文件大小为 1/32 * innodb_redo_log_capacity。在 #innodb_redo 目录下,日志文件名为 #ib_redoXX,XX 是 数字 或 数字_tmp,前者表示已使用的,后者表示备用的。例如下面这样:
#ib_redo1310 #ib_redo1314_tmp #ib_redo1318_tmp #ib_redo1322_tmp #ib_redo1326_tmp #ib_redo1330_tmp #ib_redo1334_tmp #ib_redo1338_tmp
#ib_redo1311 #ib_redo1315_tmp #ib_redo1319_tmp #ib_redo1323_tmp #ib_redo1327_tmp #ib_redo1331_tmp #ib_redo1335_tmp #ib_redo1339_tmp
#ib_redo1312_tmp #ib_redo1316_tmp #ib_redo1320_tmp #ib_redo1324_tmp #ib_redo1328_tmp #ib_redo1332_tmp #ib_redo1336_tmp #ib_redo1340_tmp
#ib_redo1313_tmp #ib_redo1317_tmp #ib_redo1321_tmp #ib_redo1325_tmp #ib_redo1329_tmp #ib_redo1333_tmp #ib_redo1337_tmp #ib_redo1341_tmp
2
3
4
每个已使用的 Redo Log 文件都有相应的起止 LSN 值:
greatsql> SELECT FILE_ID, FILE_NAME, START_LSN, END_LSN, SIZE_IN_BYTES, IS_FULL, CONSUMER_LEVEL
FROM performance_schema.innodb_redo_log_files;
+---------+-----------------------------+-------------+-------------+---------------+---------+----------------+
| FILE_ID | FILE_NAME | START_LSN | END_LSN | SIZE_IN_BYTES | IS_FULL | CONSUMER_LEVEL |
+---------+-----------------------------+-------------+-------------+---------------+---------+----------------+
| 1310 | ./#innodb_redo/#ib_redo1310 | 21996097536 | 22012872704 | 16777216 | 1 | 0 |
| 1311 | ./#innodb_redo/#ib_redo1311 | 22012872704 | 22029647872 | 16777216 | 0 | 0 |
+---------+-----------------------------+-------------+-------------+---------------+---------+----------------+
2
3
4
5
6
7
8
当 Redo Log 执行完 checkpoint 后,相应的 checkpoint LSN 就会存储在它所在的那个日志文件头部信息中,当需要进行 crash recovery 时再扫描这些文件的头部信息,找出最后的 checkpoint LSN 进行恢复。
§ 自动配置 Redo Log
当参数 innodb_dedicated_server = ON 时,会假定 GreatSQL 数据库实例尽量最优地使用服务器资源,InnoDB 就会自动调整相关参数配置,也包括 Redo Log 总容量;该参数默认不启用,更多详情参考:Enabling Automatic Configuration for a Dedicated MySQL Server (opens new window)。
§ 禁用 Redo Log
从 8.0.21 开始,支持执行 SQL 命令 ALTER INSTANCE DISABLE INNODB REDO_LOG 以禁用 Redo Log(其实也包括禁用 Doublewrite Buffer)。这是危险操作,一般不要这么做,只有在以下几种特殊场景下可以考虑:
- 仅用于性能测试目的。
- 停机维护期间,为了加快数据批量导入速度。
其他时候,严禁 执行禁用 Redo Log 的操作,否则有极大可能性会导致数据丢失、甚至实例损坏等重大风险。当发生这种风险时,可能错误日志中会有类似下面的提示:
[ERROR] [MY-013598] [InnoDB] Server was killed when Innodb Redo logging was disabled. Data files could be corrupt. You can try to restart the database with innodb_force_recovery=6
这就只能采用最高等级的 InnoDB 恢复了,有较大可能性会导致数据丢失,甚至实例都无法启动。
执行 SQL 命令 ALTER INSTANCE ENABLE INNODB REDO_LOG 再次启用 Redo Log。
§ 理解 Redo Log
§ Redo Log 写入过程
以一个 Update 事务为例,描述 Redo Log 流转过程,如下图所示:
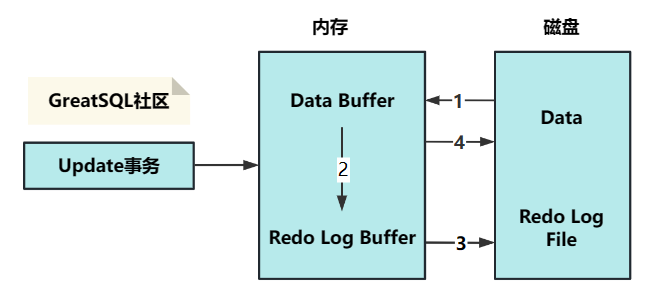
流程说明:
判断要 Update 的数据是否已经在 InnoDB buffer pool 中,没有的话就先将它从磁盘中读入 buffer pool,并修改它(产生脏页)。
生成 Redo Log 记录并写入 Redo Log Buffer。
当事务提交时,将 Redo Log Buffer 中的内容刷新到 Redo Log 磁盘文件中。
再将内存中修改的数据(脏页)刷新到对应的表空间磁盘文件中。
这里没有列出 Redo Log 和 Undo Log 的协同过程,这部分内容可以参考:事务中 Undo Log 和 Redo Log 协同。
§ Redo Log 刷盘策略
上面提到,Redo Log 是先写到 log buffer 中,再刷新到 Redo Log 文件中。下面介绍 Redo Log 刷盘策略。
以下几种情况下,会触发 Redo Log Buffer 立即写入 Redo Log 文件中:
- 当可用 Redo Log Buffer 空间不足 1/2 时。
- 事务提交且设置
innodb_flush_log_at_trx_commit=1时。 - 后台线程每秒定期调度刷新磁盘。
- 执行 Checkpoint 时。
- 实例 Shutdown 时。
- 切换 Binlog 文件时。
小贴士
Redo Log Buffer 写入 Redo Log 文件时有可能并不是立即同步刷新到磁盘文件的,可能只是写到操作系统的 page cache 中,再由操作系统执行刷新同步到磁盘文件。
这种情况下,如果发生宕机,那么数据可能会丢失。
因此,在要求数据高可靠性的环境中,务必设置 innodb_flush_log_at_trx_commit=1。
§ Checkpoint(检查点)
Redo Log Checkpoint 机制用于标识 Redo Log 中已持久化到磁盘的数据部分,从而避免重复写入,提高系统性能。及时 Checkpoint 也能提高发生 crash recovery 时恢复的效率,因为可以从最后的 Checkpoint LSN 位置处开始扫描待恢复的日志,而无需扫描全部日志。
执行 Checkpoint 时
- 将脏页从缓冲池写入数据文件。
- 更新 last checkpoint LSN 位置。
§ 两阶段提交(2PC)
为了确保事务的一致性和持久性,当涉及到事务处理时,会利用二阶段提交(Two-Phase Commit, 2PC)机制来同步二进制日志(Binary Log,简称 Binlog)与重做日志(Redo Log)。这两个日志系统分别承担不同的职责:Binlog 主要用于复制和审计,而 Redo Log 则是 InnoDB 存储引擎用来保证事务可靠性的机制之一。以下是 2PC 的工作机制详解:
§ 第一阶段:准备阶段(Prepare Phase)
事务准备:当一个事务的所有更改都已完成,但尚未提交时,GreatSQL 服务器会将这些更改写入到 Redo Log 中,并标记为“准备”(prepare)状态,而不是直接提交。同时,GreatSQL 会记录一条对应的 Binlog 条目,但是不会立即将其写入磁盘,而是将其放入内存缓冲区(Binlog cache)中等待后续处理。
检查点更新:如果启用了 Binlog,在事务进入准备阶段之后,GreatSQL 会将事务的 Binlog 条目写入到磁盘上的 Binlog 文件中。这一步确保了即使系统崩溃,Binlog 也包含了所有已准备好但未提交的事务的信息。
确认写入:一旦 Binlog 条目成功写入磁盘,GreatSQL 会通知 InnoDB 存储引擎,告知它事务已经准备好并且 Binlog 已经被安全地写入磁盘。
§ 第二阶段:提交或回滚(Commit or Rollback Phase)
提交事务:如果一切正常,GreatSQL 会向 InnoDB 发送一个提交命令。此时,InnoDB 会将事务的状态从“准备”改为“已提交”(commit),并把最终的数据更改写入到磁盘上的 Redo Log 中。然后,InnoDB 会返回给 GreatSQL 服务器一个成功的响应。
更新 Binlog 状态:GreatSQL 接收到成功的提交响应后,会更新事务的状态,表明事务已经被提交。如果之前是异步写入 Binlog,则在此阶段确认写入成功。
回滚事务:如果在准备阶段或提交过程中出现错误,GreatSQL 会选择回滚事务。在这种情况下,InnoDB 会撤销所有已经完成的操作,确保数据库回到事务开始前的状态。
§ 2PC 的好处与性能开销
- 好处
- 数据一致性:通过这种机制,GreatSQL 能够确保即使在发生故障的情况下,事务的状态也能保持一致。具体来说,如果事务已经写入了 Binlog,那么在恢复过程中可以通过 Binlog 重新应用这些事务,以确保主从复制的一致性。
- 故障恢复:如果系统在事务提交前崩溃,恢复过程可以从 Binlog 中读取未完成的事务,并根据事务的准备状态决定是否继续提交或回滚。
- 主从复制的一致性:通过同步写入 Binlog 和 Redo Log,两阶段提交保证了主库的数据修改和从库的日志同步保持一致性,避免主从复制时出现数据不一致的问题。
- 性能开销
- 两阶段提交会增加磁盘IO操作,尤其是在高并发场景下,可能会影响数据库的性能。
- 两阶段提交涉及多个日志系统之间的协调,增加了事务处理的复杂性。
总之,2PC 机制在 GreatSQL 中扮演着至关重要的角色,是确保数据一致性和完整性的重要手段。虽然它带来了一定的性能开销和复杂性,但其在保证数据不丢失和主从库同步方面发挥着不可替代的作用。
§ Redo Log 优化
Redo Log 相关的调整优化操作,主要参考以下几条原则:
- Redo Log 是以顺序 I/O 为主,不管是读还是写都是,整体的 I/O 性能还是不错的。
- 加大 Redo Log 容量有利于降低 checkpoint 的频率,缩小则可能会导致产生过多的没必要的刷盘操作,甚至于可能导致 Redo Log 不够用,导致数据库发生丢失损坏风险。
- 适当调大
innodb_log_buffer_size可以在内存中缓冲更多的事务数据,降低刷盘频率。 - 适当调整
innodb_log_write_ahead_size,一般建议和操作系统或文件系统块大小设置一致,例如 4KB。设置过小就比较容易发生 写时读,而设置太大则可能导致 fsync 性能受到一定影响(因为一次性要刷新多个数据块)。 - 从 8.0.11 开始新增专门的 log writer 线程负责将 redo log 记录写入 log buffer,并再将其从 log buffer 写入 Redo Log 文件。从 8.0.22 开始,可以通过设置
innodb_log_writer_threads来启用或禁用该线程。在高并发场景建议启用,在低并发场景可以关闭。 - 优化用户线程等待 Redo 刷新时的自旋延迟(spin delay)。自旋延迟可以减少用户响应时延(latency)。在低并发场景下,降低响应时延并不急迫,在这期间避免使用自旋延迟反而还能降低能耗;而在高并发场景下,应尽量减少自旋延迟。通过下面几个参数变量可以设置自旋延迟高低水位边界。
innodb_log_wait_for_flush_spin_hwm定义用户线程在等待刷新 Redo 时不再自旋的最大平均日志刷新时间。默认值:400(微秒)。innodb_log_spin_cpu_abs_lwm定义 CPU 使用率的最小值,低于该值时,用户线程在等待刷新 Redo 时不再自旋。该值表示所有 CPU 核心的总和。默认值:80(%)。当有多个 CPU 核心时,它可以定义超过 100;例如:150,即第一个 CPU 核心使用率 100%,第二个核心使用率 50%。innodb_log_spin_cpu_pct_hwm定义 CPU 使用率的最大值,高于该值时,用户线程在等待刷新 Redo 时不再自旋。该值表示所有 CPU 核心总处理能力的百分比。默认值:50(%)。例如,在有 4 个 CPU 核的时候,其中 2 个 CPU 核 100% 的使用率就是CPU处理能力总和的 50%。另外,该参数会考虑到 CPU 亲和性设置;例如,如果一台服务器有 48 个 CPU 核,但 mysqld 进程设置了仅固定在 4 个 CPU 核上,则会忽略其他 44 个 CPU 核。
§ 相关参数变量
innodb_redo_log_capacity用于配置 InnoDB Redo Log 容量,默认值:100MB,取值范围:[8MB - 512GB]。大部分情况下设置为 1GB - 8GB 范围是足够的。在支持在线动态修改并立即生效。8.0.30 及更高版本之后引入,在这之前可以通过设置
innodb_log_file_size和innodb_log_files_in_group来配置,见下方说明。innodb_log_file_size&innodb_log_files_in_group在 8.0.30 版本以前,通过
innodb_log_file_size和innodb_log_files_in_group组合来配置 Redo Log 总量。前者表示每个 Redo Log 文件大小,后者表示总共有几个文件。前者默认值:48MB,取值范围:[4MB - 512GB / innodb_log_files_in_group]。后者默认值:2,取值范围:[2 - 100]。二者相乘后即为 Redo Log 容量,但最大值不得超过 512GB。innodb_log_group_home_dir指定了存放 Redo Log 文件的路径。默认值为空,表示将 Redo Log 文件存储在
datadir目录下的#innodb_redo子目录下。一般不做配置。innodb_log_buffer_size用于配置 InnoDB 用于缓冲 Redo Log 的内存大小。在事务提交前,事务的修改会先写入这个日志缓冲区。默认值:16MB,取值范围:[1MB - 4GB]。大部分情况下设置为 16MB - 64MB 范围是足够的。支持在线动态修改并立即生效。
innodb_log_write_ahead_size配置 Redo Log 预写块大小,单位:字节,默认值:8192(字节),取值范围:[512字节 - innodb_page_size]。为了避免 写时读(read-on-write),建议将其设置为和操作系统或文件系统缓存块大小一致。当 Redo Log 预写块大小和操作系统(或文件系统)缓存块大小不一致时,就会发生 写时读 的情况。它必须设置为 InnoDB Redo Log 块大小(512字节)的整数倍。当设置为最小值即 512字节 时就不再对 Redo Log 进行 预写。设置过小就比较容易发生 写时读,而设置太大则可能导致 fsync 性能受到一定影响(因为一次性要刷新多个数据块)。
innodb_log_writer_threads从 8.0.11 开始新增专门的 log writer 线程负责将 redo log 记录写入 log buffer,并再将其从 log buffer 写入 Redo Log 文件。从 8.0.22 开始,可以通过设置
innodb_log_writer_threads来启用或禁用该线程。innodb_log_wait_for_flush_spin_hwm定义用户线程在等待刷新 Redo 时不再自旋的最大平均日志刷新时间。默认值:400(微秒)。
innodb_log_spin_cpu_abs_lwm定义 CPU 使用率的最小值,低于该值时,用户线程在等待刷新 Redo 时不再自旋。该值表示所有 CPU 核心的总和。默认值:80(%)。
innodb_log_spin_cpu_pct_hwm定义 CPU 使用率的最大值,高于该值时,用户线程在等待刷新 Redo 时不再自旋。该值表示所有 CPU 核心总处理能力的百分比。默认值:50(%)。该参数会考虑到 CPU 亲和性设置。
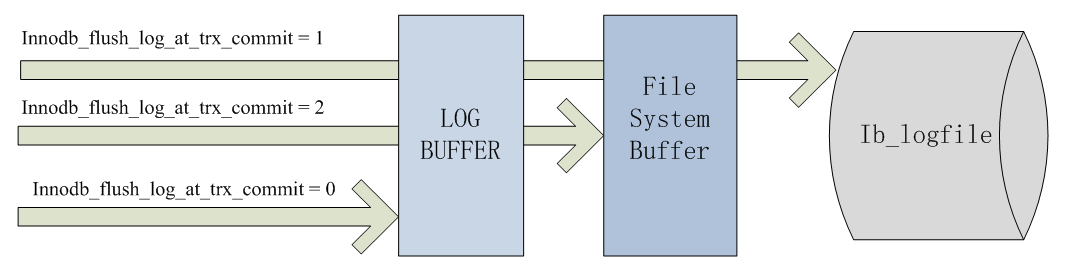
innodb_flush_log_at_trx_commit用于控制事务提交时 Redo Log 的刷盘行为模式,不同设置会影响数据库的性能,以及数据可靠性风险。默认值:1,取值范围:
- 0:事务提交时不刷新重做日志缓冲区到磁盘。每秒刷新一次。性能最好,安全性最差。
- 1:每个事务提交时都将重做日志缓冲区写入磁盘,并刷新文件系统缓冲区。性能最差,安全性最好。
- 2:事务提交时只将重做日志缓冲区写入文件系统缓冲区,每秒刷新一次。性能和安全性的折中选择。
- 为了保证数据安全可靠,请务必同时设置
innodb_flush_log_at_trx_commit = 1&sync_binlog = 1,即俗称设置为 双1。
小贴士
DDL 变更以及其他 InnoDB 内部活动相关日志刷新不受本参数影响。
innodb_flush_log_at_timeout用于控制 InnoDB Redo Log 缓冲区在没有事务提交的情况下被刷新到磁盘的时间间隔,以增强数据的持久性和安全性。单位:秒,默认值:1,取值范围:[1 - 2700]。
§ 相关状态变量
Redo Log 相关状态变量有以下这些
greatsql> SHOW GLOBAL STATUS LIKE 'innodb%redo%';
+-------------------------------------+-------------+
| Variable_name | Value |
+-------------------------------------+-------------+
| Innodb_redo_log_read_only | OFF | <= Redo Log 是否处于只读状态
| Innodb_redo_log_uuid | 1075899837 | <= Redo Log UUID
| Innodb_redo_log_checkpoint_lsn | 22026843368 | <= 完成 checkpoint 的 LSN
| Innodb_redo_log_current_lsn | 22026843368 | <= 最新 LSN
| Innodb_redo_log_flushed_to_disk_lsn | 22026843368 | <= 已刷新到磁盘的 LSN
| Innodb_redo_log_logical_size | 512 | <= 数据块大小(单位:字节),表示在用Redo Log的LSN范围,从重做日志使用者所需的最旧块到最近写入的块
| Innodb_redo_log_physical_size | 33554432 | <= 物理大小(已使用 Redo Log)
| Innodb_redo_log_capacity_resized | 536870912 | <= Redo Log 的总容量大小,512MB
| Innodb_redo_log_resize_status | OK | <= Redo Log 调整大小的进度和状态
| Innodb_redo_log_enabled | ON | <= 是否启用 Redo Log
+-------------------------------------+-------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
以上是 8.0.30 及更高版本的配置及相应状态查看方法,在 8.0.30 以前的配置方法这里不赘述,详细请参考:Configuring Redo Log Capacity (opens new window)。
§ 附录:8.0 版本相对 5.7 在 Redo Log 方面的变化
- 新增
innodb_redo_log_capacity参数,取代原来的innodb_log_file_size&innodb_log_files_in_group。 - 新增
innodb_log_wait_for_flush_spin_hwm, innodb_log_spin_cpu_abs_lwm, innodb_log_spin_cpu_pct_hwm等几个优化相关参数。 - 支持 Redo Log 并行写入。
- 支持在线禁用/启用 Redo Log。
- 支持 Redo Log 加密。
- 支持 Redo Log 归档(企业版 mysqlbackup 所用)。
延伸阅读:
- Redo Log (opens new window)
- Redo Log Configuration (opens new window)
- Optimizing InnoDB Redo Logging (opens new window)
扫码关注微信公众号
