§ Changes in GreatSQL 8.0.25 (2021-8-26)
§ 新增特性
§ 新增节点地理标签
可以对每个节点设置地理标签,主要用于解决多机房数据同步的问题。
新增选项 group_replication_zone_id,用于标记节点地理标签。该选项值支持范围 0 ~ 8,默认值为0。
当集群中各节点该选项值设置为不同的时候,就被认定为设置了不同的地理标签。
在同城多机房部署方案中,同一个机房的节点可以设置相同的数值,另一个机房里的节点设置另一个不同的数值,这样在事务提交时会要求每组 group_replication_zone_id 中至少有个节点确认事务,然后才能继续处理下一个事务。这就可以确保每个机房的某个节点里,总有最新的事务。
| System Variable Name | group_replication_zone_id |
|---|---|
| Variable Scope | global |
| Dynamic Variable | YES |
| Permitted Values | [0 ~ 8] |
| Default | 0 |
| Description | 设置MGR各节点不同的地理标签,主要用于解决多机房数据同步的问题。 修改完该选项值之后,要重启MGR线程才能生效。 |
§ 采用全新的流控机制
原生的流控算法有较大缺陷,触发流控阈值后,会有短暂的流控停顿动作,之后继续放行事务,这会造成1秒的性能抖动,且没有真正起到持续流控的作用。
在GreatSQL中,重新设计了流控算法,增加主从延迟时间来计算流控阈值,并且同时考虑了大事务处理和主从节点的同步,流控粒度更细致,不会出现官方社区版本的1秒小抖动问题。
新增选项 group_replication_flow_control_replay_lag_behind 用于控制MGR主从节点复制延迟阈值,当MGR主从节点因为大事务等原因延迟超过阈值时,就会触发流控机制。
| System Variable Name | group_replication_flow_control_replay_lag_behind |
|---|---|
| Variable Scope | global |
| Dynamic Variable | YES |
| Permitted Values | [0 ~ ULONG_MAX] |
| Default | 60 |
| Description | 用于控制MGR主从节点复制延迟阈值,当MGR主从节点因为大事务等原因延迟超过阈值时,就会触发流控机制 |
该选项默认为60秒,可在线动态修改,例如:
mysql> SET GLOBAL group_replication_flow_control_replay_lag_behind = 60;
正常情况下,该参数无需调整。
§ 稳定性提升
§ 支持AFTER模式下多数派写机制
这样在发生网络分区时,依然可以保障集群的高可用性。
发生网络分区故障时,只要多数派节点已经回放完毕,集群就可以继续处理新的事务。
§ 解决磁盘空间爆满时导致MGR集群阻塞的问题
在官方社区版本中,一旦某个节点磁盘空间满了,就会导致整个集群被阻塞,这种情况下,节点数量越多,可用性越差。
在GreatSQL版本中,一旦发现某节点磁盘空间满了,就会让这个节点主动退出集群,就可以避免整个集群被阻塞的问题。
§ 解决多主模式下或切主时可能导致丢数据的问题
官方社区版本中,是提前处理事务认证数据的。
而在GreatSQL版本中,调整了事务认证处理流程,改成放到 applier queue 里按照paxos顺序处理,这就解决了在多主模式下或切主时可能导致丢数据的问题。
§ 解决节点异常退出集群时导致性能抖动的问题
官方社区版本中,paxos通信机制较为粗糙,当节点异常退出时,会造成较长时间(约20~30秒)的性能抖动,最差时TPS可能有好几秒都降为0。
GreatSQL版本中对此进行优化后,只会产生约1~3秒的性能小抖动,最差时TPS可能只损失约20% ~ 30%。
§ 节点异常状态判断更完善
当发生节点异常崩溃或者网络分区时,GreatSQL版本能更快发现这些异常状态。官方需要5秒才能发现,而GreatSQL只需要大概1秒,这就能有效减少切主和异常节点的等待耗时。
§ 优化日志输出格式
增加更多DEBUG信息,便于排查MGR运行时遇到的问题。
§ 性能提升
§ 重新设计事务认证队列清理算法
官方社区版本中,对事务认证队列清理时采用了类似全表扫描的算法,清理效率较低,性能抖动较大。
在GreatSQL版本中,对事务认证队列增加了类似索引机制,并控制每次清理的时间,可以有效解决清理效率低、性能抖动大的问题。
§ 提高MGR吞吐量
在类似跨城IDC部署的高延迟场景下,提升应用访问MGR的吞吐量,尽量减少网络延迟对访问性能的影响。
§ 提升强一致性读性能
提升强一致性读性能,使得从库只读延迟大大降低。
§ 合并华为鲲鹏计算团队贡献的两个Patch
§ InnoDB事务对象映射数据结构优化
在官方社区版本实现中,使用了红黑树结构实现了事务ID到事务对象的快速映射关系。但是该数据结构在高并发应用场景中,大量的锁竞争会造成事务处理的瓶颈。
在GreatSQL中采用全新的无锁哈希结构,显著减少了锁的临界区消耗,提升事务处理的能力至少10%以上。
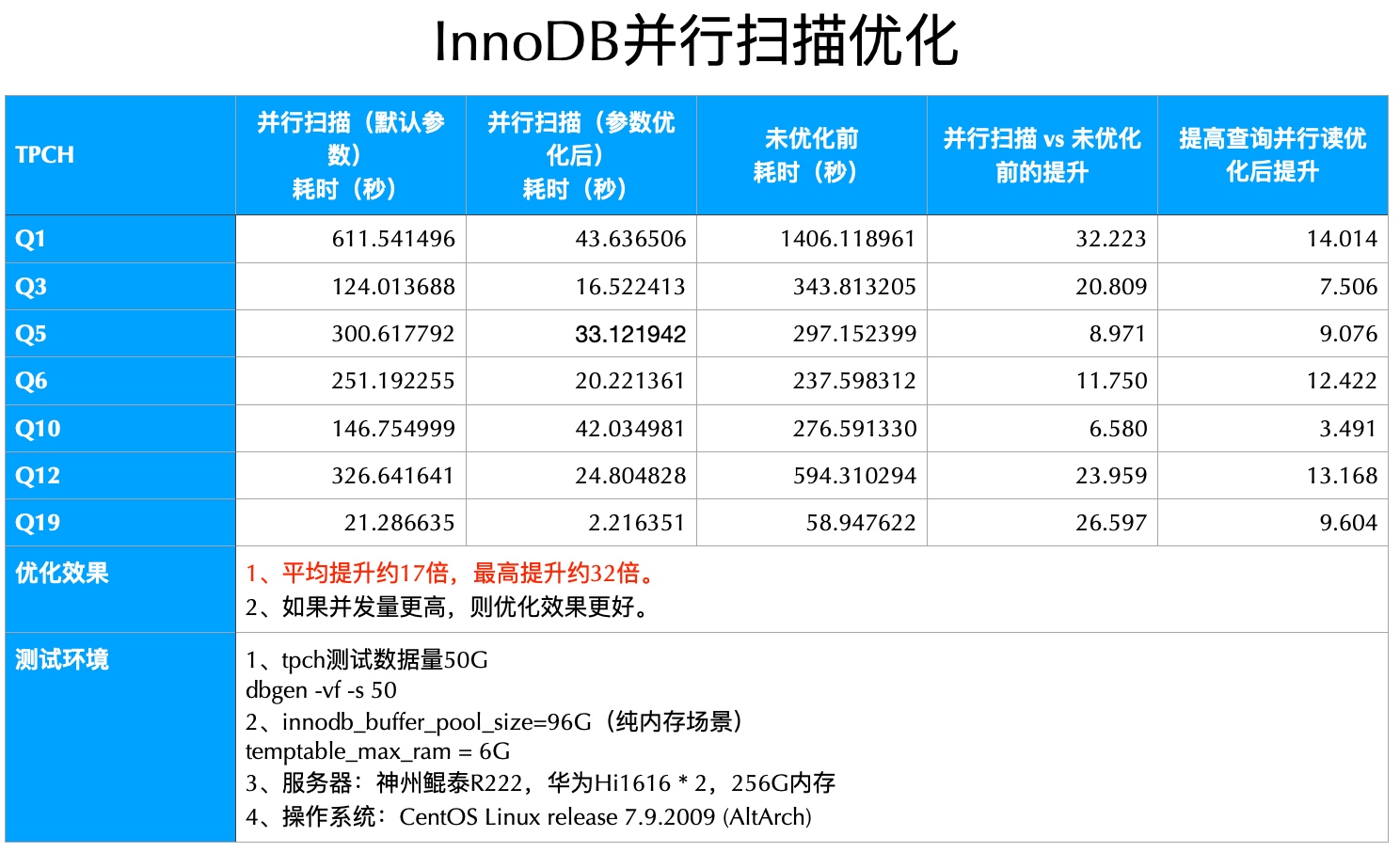
§ InnoDB并行查询优化
根据B+树的特点,可以将B+树划分为若干子树,此时多个线程可以并行扫描同一张InnoDB表的不同部分。对执行计划进行多线程改造,每个子线程执行计划与MySQL原始执行计划一致,但每个子线程只需扫描表的部分数据,子线程扫描完成后再进行结果汇总。通过多线程改造,可以充分利用多核资源,提升查询性能。
优化后,在TPC-H测试中表现优异,最高可提升30倍,平均提升15倍。该特性适用于周期性数据汇总报表之类的SAP、财务统计等业务。
使用限制:
- 暂不支持子查询,可想办法改造成JOIN。
- 暂时只支持ARM架构平台,X86架构平台优化也会尽快完成。
§ bug修复
- 修复了AFTER模式下的多个bug,提高强一致性写AFTER模式的可靠性。例如有新节点加入时,由于消息处理不当、线程同步等问题容易导致一系列异常退出集群的现象。
- 修复了多数派节点不同类型异常退出集群导致的视图更新的问题。当节点崩溃和节点退出同时发生的话,可能会导致MGR视图跟实际情况不符,从而出现一系列不异常问题。
- 修复了MGR部署在单机环境下多节点的TCP self-connect问题。相关BUG#98151 (opens new window)。
- 修复了recovery过程中长时间等待的问题。同时启动多个节点,可能会导致一直卡在recovering状态,持续时间很久(甚至可能超过数小时)。修复了几处不合理的sleep做法,解决该问题。
- 修复了传输大数据可能导致逻辑判断死循环问题。
- 修复若干coredump问题
- a)执行
start group_replication和查询replication_group_member_stats并发操作时,可能导致start group_replication启动失败,甚至节点coredump。 - b)执行
start group_replication启动过程可能失败,在销毁内部对象过程中,如果同时查询replication_group_member_stats状态,可能导致coredump。
- a)执行
§ 使用注意事项
- 当MGR集群任何节点处于recovering状态,并且还有业务流量时,【不要】执行stop group_replicationt停止MGR服务,否则可能会导致GTID紊乱甚至丢数据风险。
- 选项
slave_parallel_workers建议设置为逻辑CPU数的2倍,提高从库回放时的并发效率。 - 设置
group_replication_flow_control_replay_lag_behind参数后,原生MGR中的流控参数不再起作用,GreatSQL会根据队列长度、大小自动进行流控。 - 在MGR节点正式拉起之前,务必设置
super_read_only=ON(或者确保此时不会有人修改数据)。 - 选项
group_replication_unreachable_majority_timeout建议不要设置,否则网络分区的时候,给用户返回错误,但其它分区多数派已经提交了事务。 - 出于问题诊断需要,建议设置
log_error_verbosity=3。 - 启用InnoDB并行查询优化特性(force_parallel_execute = ON)时,建议同时调大 parallel_default_dop 选项值,以提高单个SQL查询并行度。
- 启用InnoDB并行查询优化特性时,建议同时调大 parallel_max_threads 选项值,以提高整个实例的查询并行度。
- 启用InnoDB并行查询优化特性时,SQL运行时如果需要产生临时表,则可能会报告
table...full的错误,这是MySQL的BUG#99100 (opens new window),可以通过加大temptable_max_ram选项值解决。
§ GreatSQL Release Notes
§ GreatSQL 8.0
- Changes in GreatSQL 8.0.32-25 (2023-12-28)
- Changes in GreatSQL 8.0.32-24 (2023-6-5)
- Changes in GreatSQL 8.0.25-17 (2023-3-13)
- Changes in GreatSQL 8.0.25-16 (2022-5-16)
- Changes in GreatSQL 8.0.25-15 (2021-8-26)
§ GreatSQL 5.7
