||
获得雨果奖的科幻小说《三体》中出现了一个流行词汇:降维打击。更高维度文明对较低维度文明的打击不费吹灰之力。这里的“维度”一词,提醒了我看待事物时更换一个维度,也许会有更好的理解。在研究 MySQL 数据库的数据文件时,把数据页平铺,是不是可以有不同的发现。这里的降维,就是把维度放到数据页的维度,而不是内存或者程序角度。数据页平铺,肯定不是把页内所有内容平铺,可以选择一些内容着重分析,例如:LSN 。
我之前抱着学习目的解析过数据文件。学以致用,解析完了自然要用起来才有意义。现在把解析出来的 LSN 小小的利用一下,看看又有什么收获。
刚才说到“平铺”,怎么平铺,这里也是受别人启发,线条在纸上可以画出地图,点的矩阵铺在屏幕上,可以显示出各种图像。那么数据页中的 LSN 平铺,可以展示什么内容?
MySQL 是先写日志后写数据文件机制,数据落盘是异步的,也就是 WAL 机制。日志也就是 redo log 的落盘速度决定了事务的提交速度。较小的日志,越能快速的持久化。但是 redo log 在前面飞奔,数据的落盘可能会落的很远,那么大量内存中的数据页会是脏页状态,一旦实例崩溃,把 redo log 与数据页恢复到一致的状态就会非常耗时。所以 MySQL 还有 checkpoint 机制来推进数据的落盘,保证数据文件与 redo log 的“距离”不至于太远,虽然可能追不上,保持一种若即若离的感觉。不需要太近,那样会导致IO问题,也不至于太远,那样又会导致恢复时间变长。协调数据文件、redo log 和检查点之间的关系的,就是 LSN 。InnoDB 引擎通过 LSN(Log Sequence Number)来标记版本,redo log 中始终是标记为最新的版本,数据文件中的会落后于 redo log,ChenckPoint 又会在推进内存脏页落盘时,在数据文件的数据页头部来标记 LSN。这样,我们就能通过查看数据页中的 LSN 来判断哪些数据页被频繁更新,而哪些数据页很少被用户想起,以至于很少更新了。虽然它很可能会比当前实例 redo log 的 LSN 稍稍落后,但足以提供给我们一些重要的信息:哪些数据被频繁的使用。
LSN在数据页中的什么位置呢?看看文档就了然了。https://dev.mysql.com/doc/internals/en/innodb-fil-header.html 数据文件则是由一个个数据页排排坐组成的,数据页的大小一般也会默认为16K。在每个数据页头部都会有固定的 38 字节大小 header。存储了 8 部分内容,LSN 就是第五个,它的长度固定为 8 个字节,下表也许胜过文字描述。
The Fil Header has 8 parts, as follows (38 byte):
| Name | Size | Remarks |
|---|---|---|
| FIL_PAGE_SPACE | 4 | 页的校验和(checkSum)值 |
| FIL_PAGE_OFFSET | 4 | 页号 |
| FIL_PAGE_PREV | 4 | 上一个页的页号 |
| FIL_PAGE_NEXT | 4 | 下一个页的页号 |
| FIL_PAGE_LSN | 8 | 页面被最后修改时对应的日志序列位置 |
| FIL_PAGE_TYPE | 2 | 该页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 仅在系统表空间的页中定义,代表文件至少被刷到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 当前页所属的表空间,其占用4个字节 |
LSN在文件中的位置: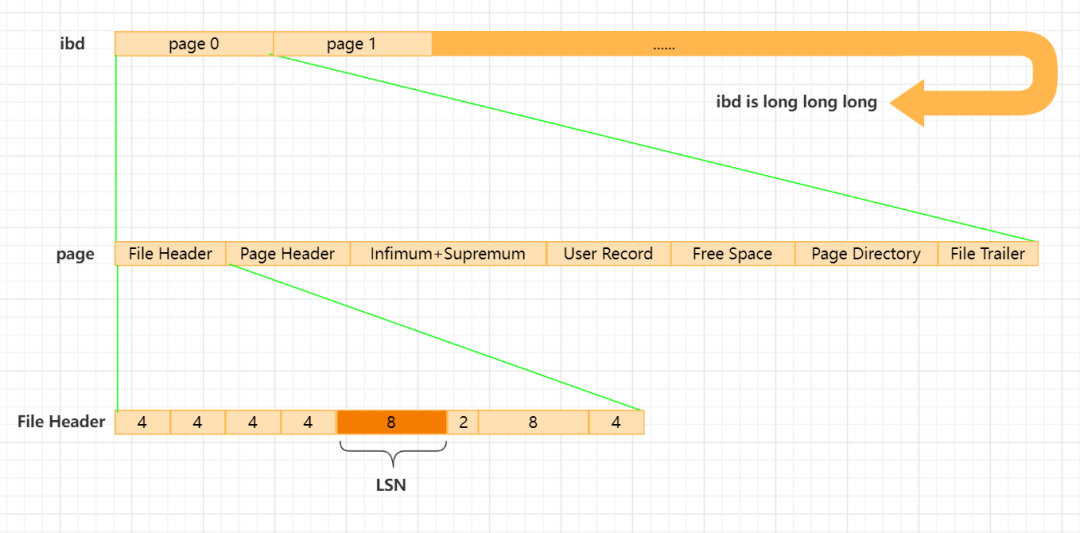
如何实现画图
既然在数据页的header里存放了LSN,那么分析所有数据页的 LSN,再通过某种形式展示出来,就可以分析哪些是“热”数据,哪些是相对“冷”的数据了。必然要讲“相对”,一部分数据比另一部分数据被经常访问,它们的“热”就是相对那部分较少被访问的数据而言。这就是通过比较它们 LSN 来实现的。
怎么展示这种冷热区别呢?就是简单借用颜色上冷暖色调来区分,蓝色是经典的冷色调,由浅蓝到深蓝的变化过程,让它来表示数据的“冷”。黄色、红色都是火焰的颜色,虽然也有蓝色火苗,这里就不要较真了,就用黄色到红色的渐变来表示数据的变“热”。
我只是固定使用了11中颜色,如果增加更多颜色来体现渐变,那么也能更清晰的体现数据页的变化情况。这本质上与增加显示屏幕像素点数量,图像更清晰是相同的道理。这里多少也能感觉出,11中颜色的渐变过程,代表了数据文件中 LSN 会被从最小值到最大值之间分成 11 个范围,每一个数据页都会根据它的 LSN 值大小落在某个区间,进而被贴上一个颜色标签。
展示数据页用一个简单的小方框来显示,方框大小只影响一个屏幕能显示多少个多少个数据页而已,大的数据文件可能到 GB 甚至 TB级别。以 1GB 数据文件为例,它就有 (1024 1024 1024)/ 16384 = 65536 个数据页,那么小方框太大了,想象一下六万多数据页那该需要滚动多少次屏幕才能显示,所以方框力求更小。这里示例用的 10px 大小。视力良好的同学,更小的方框也未尝不可。下面就是大概的样子。

代码解析 LSN 的逻辑则相对简单,单线程打开数据文件,以16384为单位解析数据页 File Header 部分的 FIL_PAGE_LSN 值,也就是每个数据页的第 16 到 24 字节的值就可以了。再将这些 LSN 值中的最大值于最小值相减,就得到整个数据文件中 LSN 的范围。把这个范围十一等分,LSN 落在哪个等分的范围之内,就用范围所属的颜色标记这个数据页,也就是表示数据页的小方框会被涂上相应的颜色
最后,这些小方框用最简单的方式排列展示就可以了,这里使用的是 HTML + CSS + JS 来实现。而解析数据文件的逻辑使用 Golang 实现,逻辑并不复杂,代码可以参考文末的链接。
执行程序后分析,会在叫做 html 的目录下生成一个 pagemap.html 的文件,在浏览器中打开就可以了。
go build pageMap.go
pageMap --ibd-file-path=sbtest1.ibd
或
go run --ibd-file-path=sbtest1.ibd
选择了很常用的sysbench压测场景。
用sysbench来初始化一个500000行数据的表,数据页大概有七千余个,还有很多 Innodb 预分配的空数据页。500000行是一个合适的行数,因为我还测试了1000000行的数据,数据页有将近两万个,生成的 page map 网页查看起来就需要滚屏好久了,为了展示的更友好,我将数据量减小到500000。
来看一下分析结果:
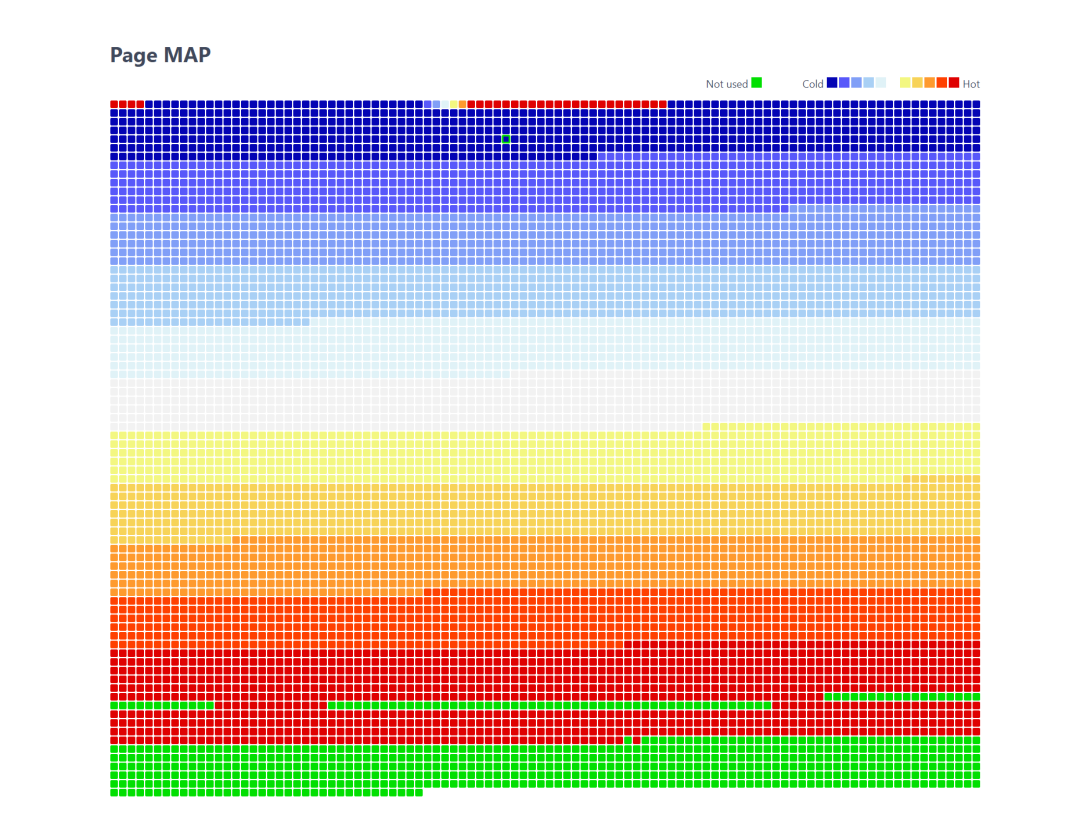
颜色分层明显,从上到下,由冷色调到暖色调渐变,这也说明,数据初始化的插入先后,必然导致 LSN 其实是逐渐递增的,如果我使用更多的颜色,而不是只用十一种,那么这种渐变也会更细腻。最下面的绿色数据页是innodb预分配的并没有使用,所以也不用太关注。
上图只是初始化数据的特点,现在使用 oltp_read_write.lua 脚本来执行压测1000秒后,来看看效果。
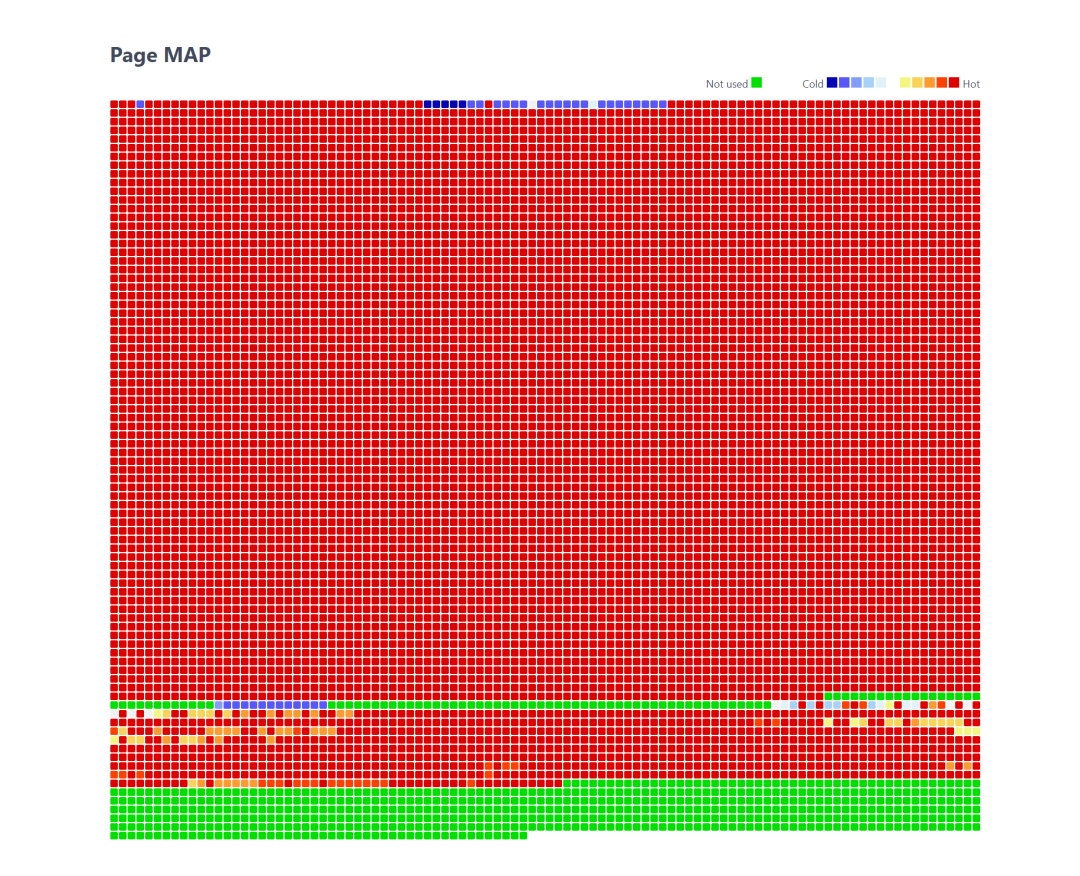
此时展示的情况就出现变化了,几乎所有数据页也都变“红”了,这是因为,压测的更新涉及到了所有数据页,它们都被更新了,彼此之间的 LSN 更为接近了,所以就会普“红”。但是细心观察会发现第一行数据页中还有部分数据页就比较“冷”,如果深入考证,就会发现这些数据页其实是非叶子节点,在 B-tree 中处在更高的 LEVEL 上。尤其是第一行的第四个数据页,它的“冷”比起周边来,更是突出。这是因为这个数据页其实是 root page,在更新数据时,其实是很少能涉及到 root page 的拆分或者 LSN 的变化了,自然它的颜色也就相对更“冷”了。
说到更多页面普“红”,说明数据更新操作覆盖比较平均。从 lua 脚本来看一下 oltp_read_write.lua 事务执行的操作,看看是不是这样。对数据有影响的更新操作:
58 execute_index_updates()
59 execute_non_index_updates()
60 execute_delete_inserts()
也就是索引更新、无索引更新、删除/插入三种操作,对行数不会有影响。
这里看一下索引更新操作逻辑,在文件oltp_common.lua 中
459 function execute_index_updates()
460 local tnum = get_table_num()
461
462 for i = 1, sysbench.opt.index_updates do
463 param[tnum].index_updates[1]:set(get_id())
464
465 stmt[tnum].index_updates:execute()
466 end
467 end
主要是:
看一下获取id的逻辑
407 local function get_id()
408 return sysbench.rand.default(1, sysbench.opt.table_size)
409 end
是从表的行数范围中随机获取。
这种表名、行数据id均为随机获取,那么压测执行时间足够长,就可以保证数据更新覆盖的均衡。
我稍稍的修改一下id获取逻辑,来影响一下更新数据范围。
先将删除/插入操作注释,避免频繁删除/插入操作引起数据页分裂或者合并。而 sysbench 的更新前后,数据大小很少发生变化,所以不会出现数据页数量变化:
58 execute_index_updates()
59 execute_non_index_updates()
60 --execute_delete_inserts()
然后修改一下id获取范围,500000行数据,只更新100000-500000范围内的数据,占比80%,再次执行 sysbench 压测1000秒
407 local function get_id()
408 return sysbench.rand.default(sysbench.opt.table_size - 400000, sysbench.opt.table_size)
409 end
再看一下输出的 html 页面展示的效果:
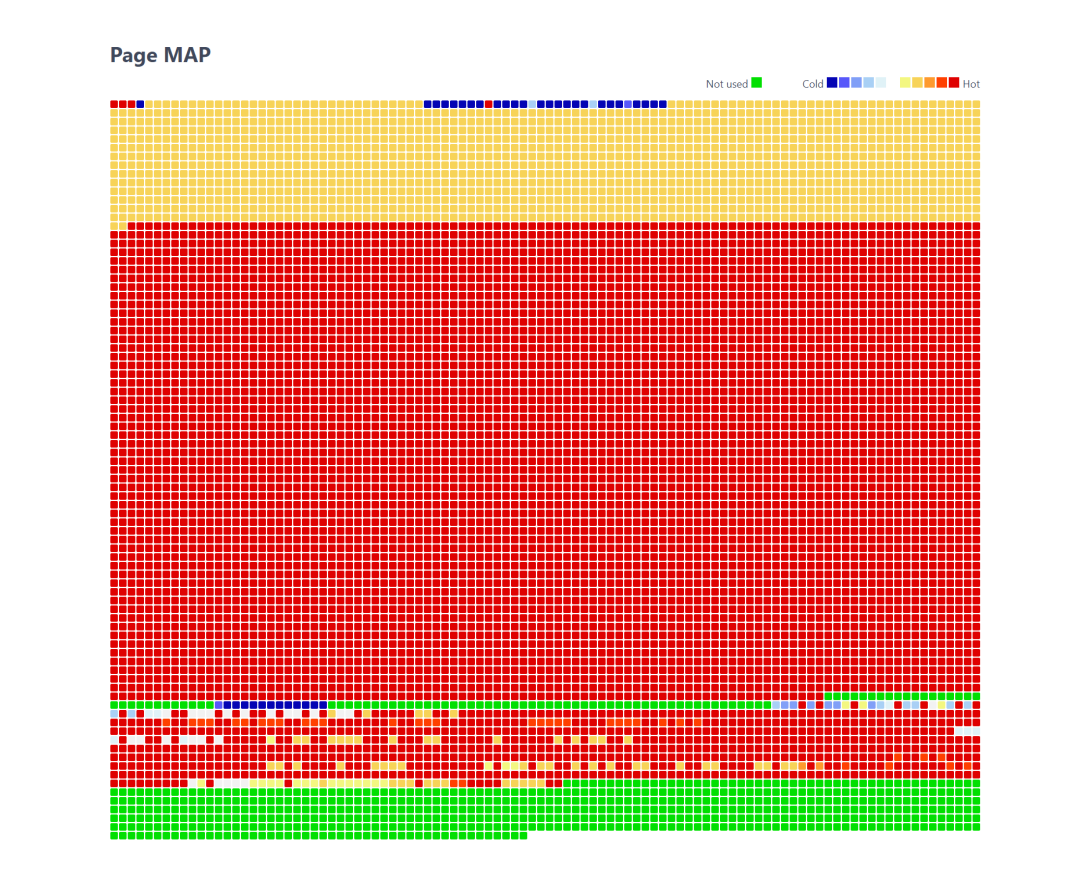
Hot 页面出现明显的区别,前100000行数据因为在最近的1000秒内没有更新,LSN 要比后400000万行数据的数据页的 LSN 要小,数据页的标记颜色相对就要更浅。如果我们持续压测更长时间,两部分数据的LSN差距就会更大,前100000行数据就会慢慢变的更“冷”了,颜色就会向冷色调演变,这正是跟我们修改过压测代码,调整了数据更新逻辑有关系。可见,更新逻辑会强烈影响数据页 LSN 的“冷”、“热”变化。不同的业务,完全可以从这个 PAGE MAP 中看出一些特点,具体哪些部分的数据会更频繁的被更新,从 MAP 中便可窥一斑。
以上就是利用 LSN 对数据更新情况进行的一个小小的分析,希望能带来不一样的体验。
如果有兴趣,下面是参考代码的链接:
https://gitee.com/huajiashe_byte/pagemap
Enjoy GreatSQL :)
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
捉虫活动详情:https://greatsql.cn/thread-97-1-1.html 社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

微信:扫码添加GreatSQL社区助手微信好友,发送验证信息加群。

合作电话:010-64087828
社区邮箱:greatsql@greatdb.com


